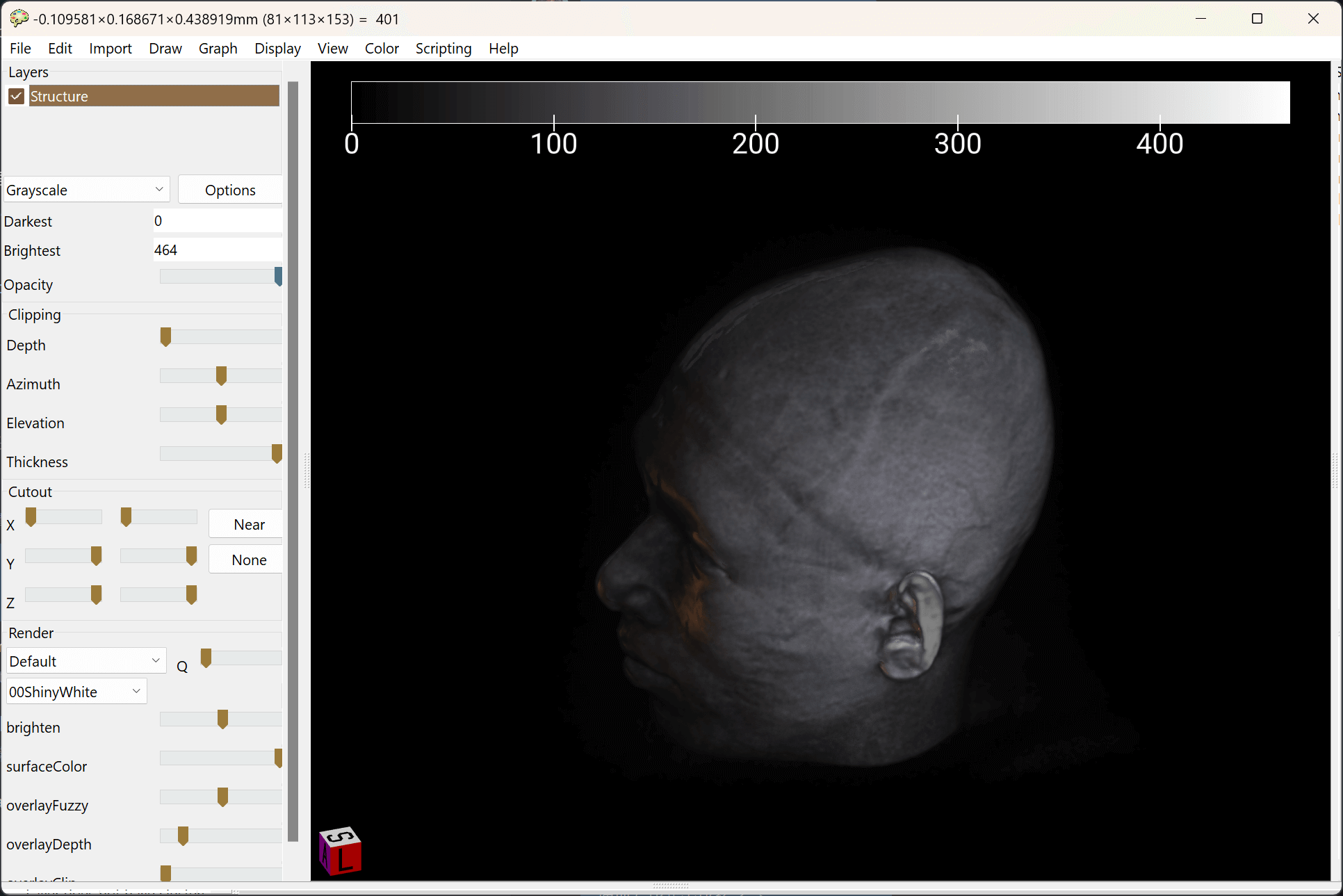
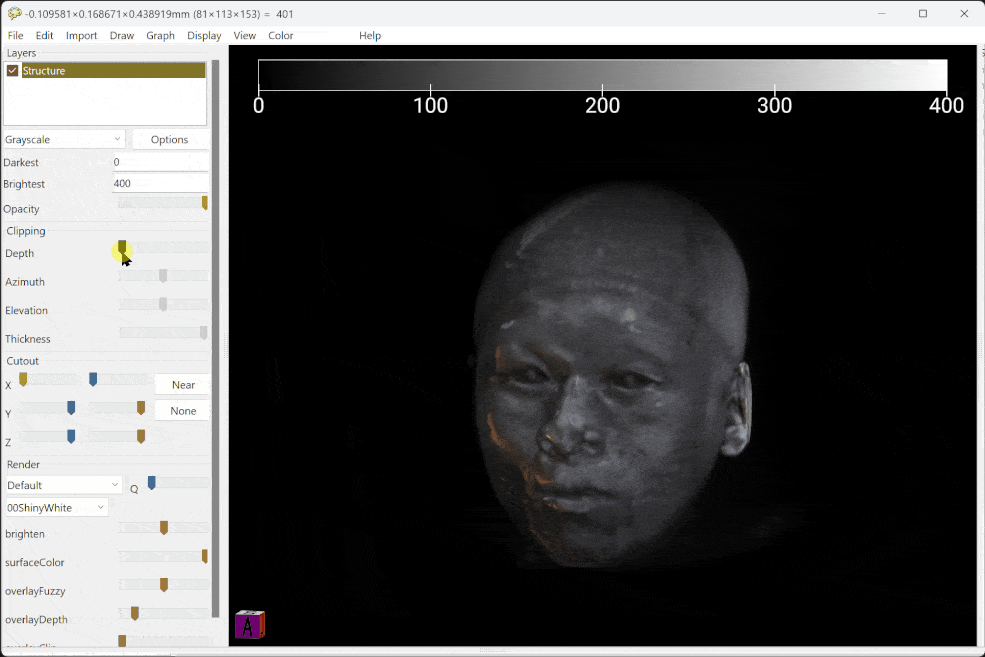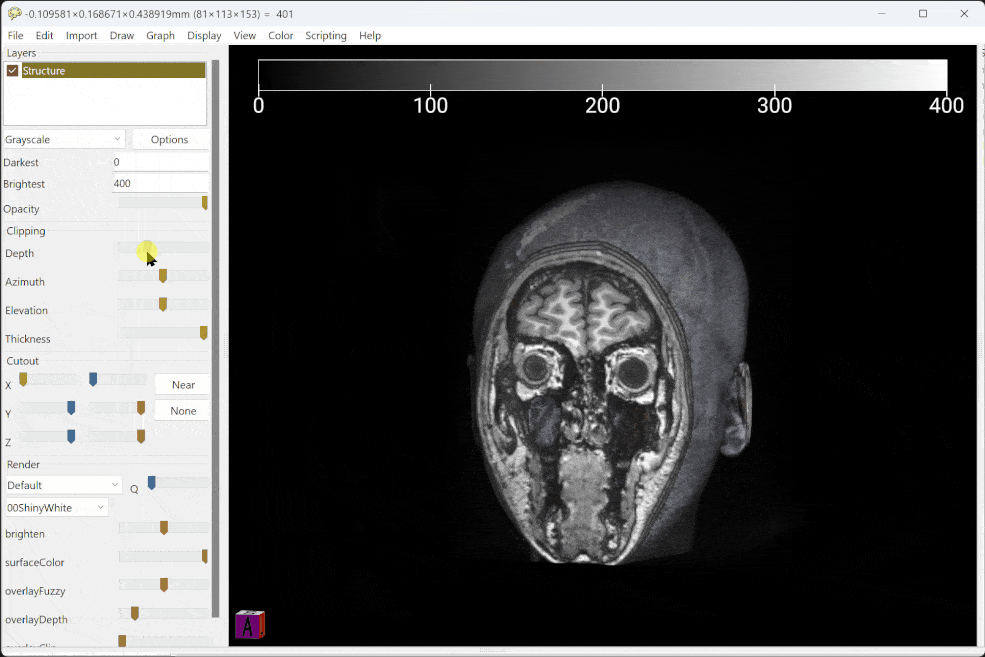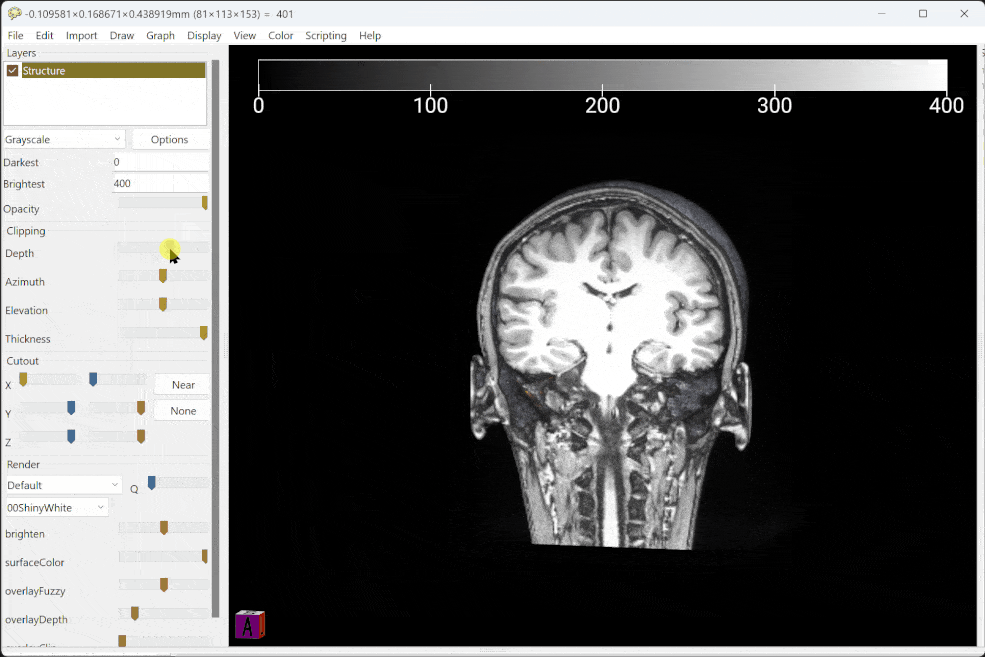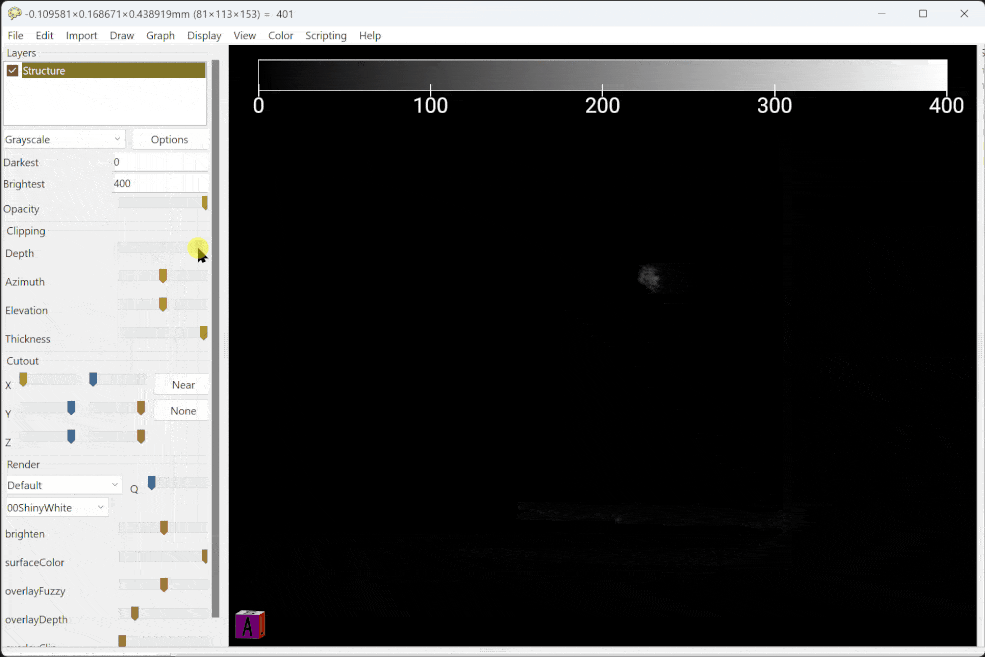
按理说每年都应该有一个年度总结,但是这两年过得实在太过贫瘠没什么好分享的,所以我决定通过一个相对较为大型的作品来总结一下这些年我的所见和所思。这就是一篇花了整个春节长假完成的大型文字作品——关于学习。在这篇文章中,我会从心理健康、认知和教育学的角度来分析现在学校教育当中最基础的构成要件,并且如何映射到每一个学科之上,对应适合且可执行的学习方法。以及在此之上,这些学科对应的能力又如何为个体的毕生发展、宏观社会的公民素养服务。
这会是一个非常庞大的话题,本篇文章也只会是一个范围有限切角,希望能给各位提供一些启发,或者安慰。
这篇文章的内容也提供了视频和音频的版本,你可以根据自己喜欢的方式进行阅览哦!
一到 29 岁这个年龄,就发现自己不再是十七八岁的小年轻了。大多数还在校的学生学习能力都超强,做一两套卷子成绩就会上去,学什么都能学得会。虽然经常跟朋友们聊天打屁说老娘永远 18 岁,但对你就你要承认的是,过了那个智力的巅峰,智商就随着你的岁数开始不断的往下掉,一直变成一个失智老人,这是一个不可逆的过程。不光我一个人在抱怨这件事情,身边一大群顶着二次元美少女头像的三十多岁多岁中年二次元抠脚大叔们,大家都在抱怨这个事情,学东西变得很慢,学什么都很痛苦。
情感与动机
一说到学习这件事情,可能很多人的这个 DNA 就动了。如果我们再加上两个字,变成一个新的词:「学习不好」,很多人的情绪可能情绪马上就上来了——你可能会觉得非常厌恶。为什么会有这个情绪?如果我们来回忆一下每一个人童年的恐怖回忆,就如果你的家长在家长会上跟老师问,说我们家孩子的成绩究竟差在哪儿是吧?老师可能就会这么跟你敷衍地讲:
孩子挺聪明的,就是不怎么努力。
上课特别爱溜号。
我说这孩子的学习不认真啊,这个觉得懂了就不听了。这个孩子特别不谦虚。
我们可以总结一下这些常见的论述是如何进行归因的:他们是在尝试把「学习问题」归因到人格因素上,或者说你的学习不好是因为你这个人不好。这个就很难办,因为人格因素很难改变的,而且它是对于一个人的全面否定。这就会引起另外一个蝴蝶效应:这些人格因素的归因会引起不良情绪,那不良情绪一旦和学习这个概念绑定到一起的时候,学习本身就会让人觉得更加痛苦。换言之,你翻开卷子的时候,你翻开你的教材的时候,你坐在书桌前面的时候,甚至把你的台灯打开的时候,不良情绪就会立刻就会压下来,这个时候事情就没得解了。
「受力分析」
我们来做一个受力分析。如图所示,小车静止在光滑水平面上,有拉力 F1 到 F6,试计算小车运动方向及加速度。这些力分别是:错误的人格因素归因,密集的考试造成的恐慌情绪,还有不良成绩带来的这种挫败感。学校大多数情况下会怎么样处理你这些不良的情绪因素呢?他会施加另外一个方向的力来处理这个问题:开个班会打点鸡血,升旗仪式校长讲话嘚啵半个小时打打鸡血,隔三差五开个誓师大会,特别的高三的时候特别爱搞这个,一模二模三模的时候各来一次誓师大会,打打鸡血。
 受力分析
受力分析
这些手段的确能调动起来某些情绪,但是长久的和学习这个概念绑定起来的,这些所谓的「负向情绪」并没有被正面解决,依然环绕在学生的身边的时候,那些「鸡血」能起的作用就会变得很有限。基本只能管两三天,对最多管一个礼拜之后就又完蛋了,这个时候怎么办呢?「一二三四,再来一次~」。
但经济学上有个概念叫做「边际效应递减」,各种誓师大会开一次还行,开两次也还行,开三次、四次它就不管用了。所以高三后半程的时候你会发现发现很多学生就躺平了。这个时候学校老师就会变得很没办法,誓师大会不管用了,其他招也没有,所以这个时候就会出现大家一起躺的情况。因此这个受力分析的结果非常简单明了,小车会向左狂奔,很多人就跟着负向的情绪跑走了。
这个时候我们要怎么办呢?我给你一招,找这个肌肉猛男和大胸美女穿着沙滩比基尼到教室里边给这个学生上课,可以的话顺便再抹点油跳个舞,学生的成绩绝对都会变好。有的人可能会说「你在鬼扯些什么」,但真有这个事儿。来给大家念个新闻啊,稿源是网易新闻,大媒体呢!
广州近日曝出教师性侵女学生的丑闻,一名英国籍女教师小美帮学生课后辅导。以成绩好就做一次为诱惑,让孩子们的英文成绩飙升。直到有家长看客厅监视器发现孩子与老师的性爱画面才起的报警让案情曝光。
很奇怪啊!一般情况下遇到这种新闻的时候,评论区一定会这个爆炸对老师的「不当行为」进行抨击,但你看这条新闻的评论区,他画风就有点不对,为什么大家都觉得好羡慕?大家都觉得这是正确的教育方法?大家都觉得年轻的时候如果也有这么一个老师,他也会变得爱学习?咦?这是怎么回事呢?
但我跟你讲这个事情在这个世界上是不存在的,后来广州公安就发了公告说这其实是一个「假新闻」。但我们从评论区当中迸发出来的情绪可以看出,说不定这个事情还真的有用,它是一个更加强的这个情绪,能够和以往的「负向情绪」相抗衡,把学生往前拽。但可惜这个世界上没有这种好事情,真是可惜,真是可惜 ¯\_(ツ)_/¯。
我们可以总结一下上面讨论的内容:如果我们把「学习动机的存在与否」归因到努力和认真上的话,这个事情一般就会变得无解。我会更加倾向于归到另外一个归因上:勇敢。
勇气
为什么我会把「学习的动力」归因到勇气上呢?因为对于很多成绩不好的人来讲,坐在书桌前面的时候多半会有很强烈的情绪反应,这个情绪反应是「孩子比较怕这个东西」,怕的是「调动起了那些不良回忆」。比如说,老师会训学生,家长会非常严厉的批评自家的小孩,孩子的的作业可能没有办法拿一个「优」,期末考试、期中考试、「堂堂测」的试卷上那些历历在目的「红叉」,那些「恐惧的回忆」和「学习」这个概念连接在一起的时候,会调起一种强烈的「害怕」的感觉,让一个人没有办法产生动力去学习。
「真的猛士,敢于直面惨淡的人生,敢于正视淋漓的鲜血」,这句话是非常、非常、非常适合用在学生身上的。不管你在考研也好,你在准备出国也好,你在高考也好,你在中考也好,我觉得这句话描述的非常好。只要有勇气坐在桌子前面,翻开那本书,所有的学生,你都是好样的,你都非常的勇敢。
很多人都没有办法产生一个动力去面对这件事情,去翻开那本书。因为对于大多数人来讲,尤其是对于大多数中国的学生来讲,学习这个事情大多数绑定的都不一定是一个好的情绪。特别对于中国的大多数学生来讲,尤其是在应试的这个框架下面来讲,这个过程一定是痛苦的,因为我们的文化鼓励「苦学」。
苦学
事实上「苦学」是一个典型的错误归因,它把「通过学习获得成就」的内在原因归因到了「能吃苦」这件事情上,但这是一个错误的「人格归因」。在任何情况下,「吃苦」这件事情一定不会是一个正向积极的信息,通过深入的挖掘,通常会发现会有一个更加强大的力量在与之抗衡,并且推动这个人「努力向前」。这些动力可能是「成就感」,可能是「认同感」,可能是「终极价值」。发现这些因素的过程实际上就是在梳理一个人生命经历脉络的过程,「能吃苦」通常不是结果,也不是人性当中真正在散发光辉的要素。
一个故事
通过上面的这些分析,我们其实共同完成了一次「心理动力学分析」,并且构建了一个理解学习动机的框架。在这个框架下,鸡汤和鸡血是没有用的,鼓励「吃苦耐劳」的道德说教也是没有用的。因为它没有打中那个真实的归因,它没有解决那个真实的潜在的情绪。特别是对于那种所有的成绩都很难烂得非常均匀的学生来讲,他们真正需要的是一个有效的社会支持系统。有效的社会支持系统是一个能够被理解,被共情的氛围。能够有人帮这个学生分析出来,你现在的感觉是什么,你现在的情绪是什么。能够有人让这个学生意识到自己是「被陪伴」的,告诉他「你不是孤独的,大家都能理解你」。
我生命经历当中有一个故事让我印象非常深刻,我上初中的时候我们班有一个男生,高高大大的特别帅,也非常有个性,跟班里的男生相处的特别好。但恰恰我们班主任是一位非常精致保守的女性,她会希望班里的所有学生都像小绵羊一样听他的话。但是很有个性的学生和她处不来。你不能说这个学生「有问题」,有个性不是坏事情,但这个老师又对付不了这样的学生,他们两个人之间就会形成一种上下相互非常强烈的对抗。班里的其他学生看起来都非常看不下去,两个人之间非常针锋相对,气氛非常非常的焦灼,两方的情绪都很激烈,打得昏天黑地。
这个男生表面上看它是很快乐的,他很享受这个过程,和班里的很多男生打成一片。但是我印象非常深刻的是他的书桌上刻了一句话,用笔刻直接刻在了桌子上的,那个东西你你是抹不掉的,那句话是「没有人理解我」。
他的班主任不理解他,可能他家里人也不知道他究竟的情绪是什么样的,甚至他自己都不一定知道那个情绪是什么,那究竟有谁理解他?没有人理解自己的情况下,人就会感到「孤独」,就会有「恐惧」,就会有那些负面情绪环绕在身边。班主任就是教数学的,那你觉得这样的孩子数学可能好吗?我觉得很难,事实上就是他的成绩的确也没有很好。这个就是一个螺旋向下的过程,你成绩不好,老师就盯你,然后你又不喜欢这个老师,一上一下交相呼应,这个成绩就螺旋向下了。
有效的社会支持系统
所以,一个有效的社会支持系统是非常重要的,它带来的是一个自由探索的一个安全感。
自由探索是什么?在学习的场域里边,学习的过程实际上就是「探索」的过程,你不懂的那些知识,实际上对个体来讲都是潜在有危险的东西。在探索它的时候,是需要一定心理资源的。这个时候如果没有没有一个有效的社会支持系统,这个能量的来源就会是一个问题,没有心理资源,就没有办法「启动」和「维持」学习的动机。
所以有的时候我会说,交个女朋友或者交个男朋友是有用的。因为它是一种安全感的来源,可以帮你产生那些你真正迫切需要的那些心理资源。
但我们总能听到另外一种说法:「一天天不知道好好学习,净知道处对象」。这其实映射到了另外一个问题:心理资源、情感支持都有了之后,如果他还是没有积极学习动力的话,那肯定是其他地方出问题了。我们要做的是去找其他的问题,绝对不是「处对象」这个行为本身有问题。一般情况下,初中生到高中生也到了那个岁数了,基本上男生会勃起、女生月经的时候,就需要认真学习和探索如何建立亲密关系了。
在这里我觉得唯一需要注意的是安全性。带好安全套,不要搞怀孕了,不要搞出大出血。特别是一对男生或者是一对女生相处的时候,要把手指甲剪干净,小心不要搞出肛裂之类的,要注意卫生不要搞出感染。这些知识都是要提前储备好的,不要搞出事情来甚至搞出人命,保护好自己是最重要的。至于其他的我个人觉得,到这个年龄,会有自由探索身体的欲望的时候,就还是要让他做下去。持续的压抑,最终到某一个时间点都会出问题。
但可惜你单身~嘿!你找不到女朋友~你 30 岁了还是大法师~
哎,我也马上就 30 岁了,马上就能搓出火球来了,哈哈哈哈哈哈哈哈!呜呜呜呜呜呜呜——
 有效的社会支持系统
有效的社会支持系统
说回正题,对于学生来讲,社会支持系统是一个最重要的基础,对应的表象才是学习的动机。很多时候我看到的是动机,但藏在下面这个社会支持系统是很难见到的,所以常常会被忽视,这就非常可惜。
能力与方法
除此之外,中段的学生会常遇到的一个问题是「偏科」。就是总有一两科学不好。这个事情可以从两个维度来看,能力为度和情绪维度。
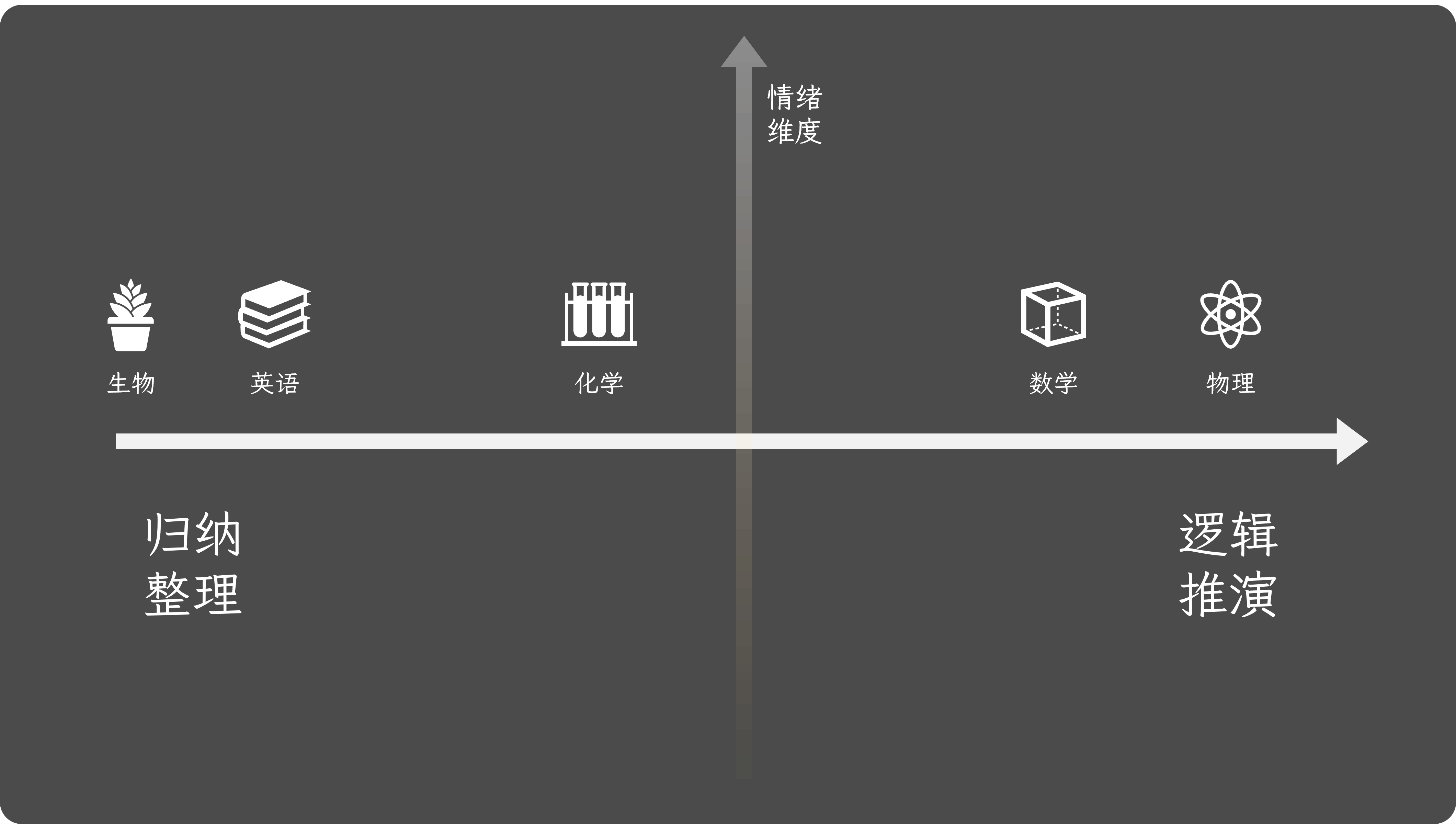 和成绩有关的两个维度
和成绩有关的两个维度
能力维度指的是,学生真的有没有具体的能力的去解决这个科目所对应的问题。能力维度是一个光谱,不同的学科映射到这个这个光谱之上,光谱的两端对应的分别是「归纳整理」和「逻辑推演」。我们把所有的科目排在这个光谱上,就能看到其实生物和英语是一个极端考验归纳整理的一个能力的学科,但是数学和物理是极端考验逻辑推演的一个学科,物理要比数学更深一点。
另外一个维度就是情绪维度,比如一个学生,推理能力都非常强,但他的数学老师很鸡掰,两个人之间就是不对付,这个情况下数学这个科目大概率是完蛋的。
如果把这两个因素拉到一个三维空间里边的话,最终得到的那个结果就是学生的成绩。
归纳整理
生物和英语是两个非常考验归纳整理能力的科目,更进一步的,在考察的是概念网络的形成、概念理解和应用的能力。
生物
生物这个科目的学习主要是在掌握大量零散的概念,辐映到考题上就是大量的「选择题」和「填空题」来考察学生是否掌握了某些「概念」的含义。具体落实到认知原理上,实际上就是通过构建概念网络来掌握这些大量的零散概念。这个时候你可能就会说,「听不懂你在共三小啦,你说人话好不好?」
我们讲的再直白一些,实际上暴力 K 书就好。无论是还是英语,基本上都是大力出奇迹的一个科目,你有大力的给他灌下去,那个成绩自然就会有。经常有人会问我说这个生物学不明白怎么办?我都会跟他讲,抄书咯。
抄教材是非常有用的,但这个「抄」需要抄的有策略。有一些老师罚学生抄抄东西,比如抄课文,或者有一些很鸡掰的要学生抄练习册,扉页都抄目录都抄,抄的就非常盲目。通常这些「罚抄」的目的都是「让学生长记性」,但我们最终的目的还是希望让他能够学会这个知识,抄只是一种手段。如果我们只是「为了抄而抄」,只是为了所谓的「惩罚」,那这就会塑造一个不良的情绪,在这里一旦不良情绪起来了,他就会对学习这个概念本身产生一个负向的连接,后面的事情就很难搞了。
所以我们要搞明白「为什么抄」和「怎么科学的抄」。今天我在这边提出一种可行的可能的方法,实际上我就是通过这样的一个办法,我把我的生物给 K 到了一个顶标水平?
 随便打开必修一挑一页
随便打开必修一挑一页
具体的做法是这样的,打开一本生物教材,比如说现在我们看到的是「必修一」,这里有一句话,实际上这句话里面就有很多可以考的知识点,既可以被改写成填空题也可以被改写成选择题。除了最后一句话是淦话,我们把它划掉,剩下的内容可以被拆成五个考点,这五个知识点当中有各种各样的概念,这样抄把这句话抄下来之后,把所有你认为可能出题的地方或者是专有名词抠成空白:
- 生物圈中存在着众多的单细胞生物,如【 】、【 】 、【 】 等,单个细胞就能完成各种生命活动。
- 许多植物和动物是多细胞生物,它们依赖各种【 】 密切合作,共同完成一系列复杂的生命活动。
- 例如,以【 】 为基础的【 】与 【 】 之间的【 】 和【 】 交换。
- 以【 】、【 】 为基础的生长发育。
- 以细胞内基因的【 】 和【 】 为基础的遗传与变异。
这样我们就得到了一个类似「学案」的东西,但这个是你自己抄出来的一个学案,相对来讲会更加适合你一些,因为你是你主动发现的内容。接下来我们要做的是,对着这个列表在脑子里边快速的过,尝试把这每个词都填进去。如果填不进去的话,就代表这个东西你不知道它是什么。这个时候我们要做的就是回去翻书重新看,直到你能够把所有的空都填满。
接下来尝试用纸笔来填,用一张白纸把每个空格的答案都写出来,填过一遍之后把这个纸扔掉,然后再填一遍,直到你能把这个知识点每一个知识点都能够填对为止。这个过程就是一个熟悉概念的过程。
在熟悉了每个独立的概念之后,我们还可以换个姿势抄,坐着抄完躺着抄,以某一个独立概念为核心把所有的教材整理一遍。比如说我们以「基因」这个概念为例,「基因」或者「遗传」这个概念在生物学必修一、必修二、选修三这几本书涉猎。我们要做的是把它都抽出来,打碎了重新整理一遍。这个过程实际上就是通过专题的方式重新组织概念的一个过程。
你可能会问「分子与细胞」这本书里里面怎么可能会有遗传哦?但刚才我们看的那句话里就有呀:
以细胞内基因的传递和变化为基础的遗传与变异等等。
必修二的「遗传与进化」就更不用说了,字面意义上都是和「遗传」有关的知识点。选修教材「现代生物技术科技」也都是一样的:
- 以细胞内基因的【 】和【 】为基础的遗传与变异。
- 生物的性状是由【 】决定的。
- 这些性状是由【 】决定的,这些因子既不会【 】也不会【 】。
- 每一个【 】决定一种【 】。
这个过程实际上就是尝试把每一个线性的概念重新组织一遍,最后组织成网络,这个过程就是构建概念网络的过程。概念网络构建起来了之后,你再看到一个概念的时候,它可以快速的激活周边的概念,对应到现实面的情况就是:我们可以非常快速准确的答对每一道题。
难度降级
这样做的一个过程被称作是难度降级。
对于很多生物成绩不太好的学生来讲,直接上去做题是比较难的。题海战术实际上是用非常非常大量零散的概念去轰击你的认知系统,如果你对概念不熟悉、找不到这个概念在哪里,它他周围的概念在哪里。概念上下文都找不到的情况下,题目就很难做对。这次做错了没记住,下次做到了还是会做错,这就是很典型的「常做常错,常考常新」。如果你真的觉得这个东西很难的话,就把所有的知识拆解成原子化的知识点,归纳到知识网络里面,通过「填空」的方式去掌握某一个单独的概念,它绝对是要比直接做题的难度要低的。
这个时候可能就会有人说「我有错题本呀」,事实上「错题本」处理「生物」这种科目能力是有限的。通过考题和错题本的方式来掌握题目但每一个知识并没有构建起知识的链接,每一个概念都是孤岛,他没有办法建立成一个网络,遇到新题目的时候激活就会很困难。用比较老派的说法就是很难「举一反三」。
有些人可能会说「我可以把相同类型的题相同考点的题整理在一起,这样不就有网络了吗?」但其实以这种形式构建的网络,相对来讲还是很稀疏的。它的连接没有那么强:因为你很难去把所有的考点都覆盖到。就算大力出奇迹把所有知识点都轰击到了,对于一般人来讲也很难做到像课本一样系统化,因此通过这种方式进行知识整理的方式效率就会低一些。
总结一些,对于生物这种考察知识点掌握的科目,尝试通过「蒙特卡洛投点」的方式来学习,效率是非常差的。特别是对于那些生物成绩本身就很弱的学生来讲。这种题海轰炸就只是单纯的一次错次次错,只会带来挫败感。知识之间如果没有办法形成连接的话,这些概念就会不好记,所以重要的是怎么样来形成概念网络,怎么样创建概念之间的连接。
考研心理学
同样,它也比较适用于考研,特别是像我这种准备心理学考研的学生。
 考研笔记
考研笔记
这个就是我的考研笔记,你可以从这个考研笔记上看到我在做的,就是把教材当中所有的知识点抠成填空题。心理学考研变态的点就是,你把高中三本生物叠在一起都没有那一本普通心理学厚?那个教材真的是砖一样能砸死人。
考试考的内容绝对不会脱离教材,所以我们要做的事情就是老老实实的把教材里面所有的知识全部都拉出来,一条一条的记住。
 第二次的笔记整理
第二次的笔记整理
第二轮笔记整理也是类似的,把所有教材里面对应一个「概念」的知识点全都抠出来做成专题。比如说我们心理学当中有个概念叫做「记忆」。普通心理学会告诉你记忆是什么,认知心理学当中会告诉你记忆这个研究是怎么来的,实验心理学可能告诉你有哪这个实验之上有哪些实验范式和记忆有关,心理学史会告诉你有哪些人去专门研究记忆。通过这样的整理我们就形成了一个非常完整的脉络,这个时候就是构建一个概念网络的过程。同时这种方法会让只是变得比较好学,因为它比较简单,它会比你 K 考研题要简单很多,因为考研一年就考那一次,我们就只有那几套题,传统的题海战术在这个体系下就会完全失效。
你会发现我整理笔记的形式会非常的多样,个人认为形式其实最最不重要的,你怎么样做都好。比如说在我的笔记里,有的时候就直接把知识点罗列起来,因为这些知识足够直截了当;有的知识是多层结构或者是一个流程结构,我可能会画个图;有一些知识真的层级太深了,我真的搞不定了,这个时候我就会用思维导图来整理它;对于那些有多个维度的知识,表格就是一个更好的方式。
再比如像心理统计学这种科目,它非常的「理」,它不会直接考这个东西的概念是什么,这个情况下我就更倾向于整理电子笔记。电子笔记允许我快速的把网上各种各样的这个知识汇集到一个地方。比如说,同样的一个统计方法,从贝叶斯学派和频率学派都会发展出不同的理解方法,通过这些理解方式,我们可以更构建起对于一个方法或者统计体系更加立体的理解。
除此之外,比如说各式各样的钢笔、花花绿绿的墨水、花里胡哨的本子、奇奇怪怪的插图。只要他能让你开心,你就买都买,都给他买下去,大量的买,买得起你就买。如果有人跟你说你这人怎么这么不务实,你就让他去吃屎。我们的最终目的是要建立的是一个和学习有关的积极情绪,学习一定是辛苦的,那这些乱七八糟的东西对学生来讲能够让人觉得「开心」,能够和「学习」的「痛苦」形成足够的对冲,那就是极有价值的。至少我们翻开笔记的时候,提起笔再做笔记的时候,会觉得稍稍的开心一点,那是一个苦中作乐,一种慰藉。
这就是和生物这门课有关的一些学习经验,你倒不一定非要用这些方法,只需要理解其中「难度降级」的思路就好,你会有适合你自己的方式,只要想办法把难度降到自己的舒适圈里面就好。
嘤语
英语这一科考的是「语用能力」,即怎么「使用」一个语言。在中高考和考研的框架下,语用能力更多的其实是在考验「阅读能力」——试卷的绝大篇幅都集中在「阅读题」上。一说做阅读怎么样才能看得懂,很多人就会提到「背~单~词~」。
背♪单♬词♭
平时学校教育都是怎么教英语的呢?上课的时候先打开教材的附录,把单词念一遍,留作业单词抄一行,把这个单词背下来。明天早上晨读的时候,码着单词表一个一个的读,课前的时候再把单词听写一遍,一个字母都不能拼错否则就是不合格,你只要错的多了就会被罚,怎么罚呢?抄单词呗,再多抄几行,仿佛是某种无尽的轮回。
我跟你讲对于大多数人来讲。这个是没有用的。不光这个没有用,还有更没用的。一提到要高考啦,要考研啦,要背单词啦,就拿着单词表从 A 开始背。这个梗都被用烂了,但烂梗请允许我再用一遍:单词表再告诉你什么呢?放弃吧(Abandon),这样做是不正常的(Abnormal),你的智商是缺席的(Absent),这件事情很荒谬(Absurd),你在虐待(Abuse)你自己。
事实上我上学的时候,单词听写没有一次合格的,但是我的英语成绩就是很高。我的英语老师也觉得很奇怪:「诶?这个人好奇怪耶,为什么单词考试一次都没有合格,但是他的英语成绩是高的?」。事实上你也不能说我没有在背单词,我只是没有一个字母一个字母背,其实那些单词的形状我都认识,大概几个音节,什么开头什么结尾,哪里凸起来哪里凹下去。大多数情况下认识到这个水平就够了。
这些传统方法犯了一些很本质的错误:一个失当的难度梯度和一个错误的学习目标。
课程教学论当中有一个知识我觉得非常好:对于一个知识的掌握,它被分成三个水平,「知晓」、「理解」和「应用」,这是三个递进的水平。对于英语考试来讲,大多数情况下只要「知晓」和「理解」就行了,即我们只需要知道这个单词的意思是什么,因为考试更加侧重考察「阅读能力」而非完整的「语用能力」。而我们在读单词的时候不是一个字母一个字母念的(i·n·t·e·r·n·a·t·i·o·n·a·l·i·z·e),我们是在把它当成一个一意群来读的(in·ter·na·tion·al·ize)。你可以根据一些词根来推断一个词汇的意思是什么,大多数情况下,我们在快速阅读文本的时候,扫过每一个单词时都只会看几个字母,抓几个重点,就知道是什么意思了。所以大多数情况下不需要一个字母一个字母的去背。除非为了写作练习可以储备单词量,否则背拼写的意义不大。
大量阅读
这样我们就省下了很多不必要的时间浪费,省下来的时间可以做一些真正有意义的事情:阅读练习。我高三时的英语老师有一句话讲得非常非常的好,叫「每天做四篇,高考一百三」——每天做四篇阅读,稳定扎实的做。每做一篇阅读,英语能力就会有一个微量的提高,这种提高小到难以察觉,但是日积月累,无论是阅读速度还是准确率都会有稳步的提升。这个和排位赛是一样的,做一篇经验就多一点点,不做就掉下去,一天不做就掉下去一点,一周不做、一个月不做、半年不做,阅读能力就会逐步退化,最后就变成智障。所以有另外一句话:「一天不做变笨蛋,一天不做变笨蛋,バカ~バカ~」。
「四篇」这个量实际上不是一个硬性的标准,一般我会推荐上限是四篇,不要做太多,会很累很难坚持。下限的话,至少一天要做一篇。唯一的标准是这个量会让你觉得舒服,你如果英语的水平稍稍弱一些的话,少做一些也没有关系,只要让练习量恰巧在舒适圈之外一丢丢就好。不要不要走太远,走得太远就会疲劳和受挫,无异于长远的习惯养成。
在题量这件事情上,有一些老师就很有毒:怎么提高英语呀?「精读泛读呀」。道理大家都懂,但是这类老师会用冲击疗法一天狂留六七篇阅读当作业。但是我们要意识到一件事情:对于那些英语成绩不是很好的学生来讲,处理每一篇外文语料都是非常消耗认知资源的,可能在前两篇的时候学生就已经处于一种高度疲劳的状态,没有那个心理资源再去处理后边的阅读题。没心理资源了怎么办?就开始懵了嘛,应付作业谁不会呢,ABCD DBCA TTFFTT 作业一交,解决~
这个时候惯用的归因方法是是「这个学生学习不认真」,但实际上更深层的原因是心里资源的枯竭,这是一个不容易被察觉到的点。所以我们说,一个适合自己的训练量是重要的,一般推荐一天最高不要超过 4 篇阅读。因为对于大多数学生来讲,每日四篇以上的练习量一定会让人处于高度疲劳的状态,特别是我们还有其他各种事情要处理的时候。当然,每天做一篇、两篇或者三篇也是可以的,通过逐步缓慢的提升训练载荷,在半年甚至一年的时间里面逐步适应每天做四篇的训练强度就好。重点是要稳定持续的做,做一篇能力就会提升一点,再做一篇又会提升一点点,越做越多能力就会越筑越高。
精读与泛读
在有一定的这个积累了之后,我们就可以开始讨论「精读」和「泛读」这两件事情了。
精读的具体做法是:题目大概看懂了,答案填上了,对完答案简单看一下哪里错了是怎么回事,就可以把它扔掉了。平时在做非真题习题的时候经常会遇到「玩命抠答案」的情况,但模拟题命制过程的思维不一定那么严谨,有的时候可能会出现一些比较怪的这个问题,或者模棱两可的问题(比如两边答的都挺对,但是你要挑更对的,但又没有找到那个更对的答案,于是就选错了)。对于泛读练习来讲,抠答案的必要性非常小,因为我们的核心目的是练习语料阅读的熟练度,而非揣测命题人的奇怪意图。
泛读的处理就需要更加认真一些:延续之前谈的思路,还是找一个让你舒服的训练载荷——对于每篇阅读我们只练习翻译一个句子,记住两个单词。
我们先来看怎么练习翻译。翻译练习的核心是从语料当中找出一篇我们看不懂的话,拿出来研究它是什么意思。以高三的教材当中的一篇课文为例,有这么一句话:People Celebrate show that they are grateful for the year’s supply of food。如果你觉得这句话没看懂,要试着翻译它,我们要怎么做呢?
 错误的翻译方法
错误的翻译方法
有些人会这样翻译:「人们庆祝表示他们感谢一年的食物供应」。这不是一句通达的中文,但很可惜非常多的考生在进行句子翻译的时候都会这么做。但这种翻译不会让你的语言能力提升,正确的做法是提取文本的含义并且**「重新组织成为有效的中文」**,比如:「人们通过庆典的方式来表达自己对于一年以来能够吃到食物这件事情的感激之情」,这个过程被称作「意译」。接下来我们拿着这个翻译过的文本进行复原英文,看看自己究竟有没有理解没看懂的那句话。我们复原出来的英文不一定和原文百分之百一样,这是正常的,但是我们要注意自己写出来的英文当中有没有包含那些「原文中不会的单词」和「你不会的语法结构」,想办法把它用到。这样一来一回,语用能力就会有提升。
做阅读题,特别是对于高中和考研英语来讲,重点并不是 ABCD 能不能选对,而是语料究竟有没有透彻的看懂。
堆量的必要性
和「应试技巧」不同,语言能力的提升是一个非常缓慢的过程,每一次练习带来的改变都是相当微小的,所以「学英语」这件事情才会让很多人感到挫败。实际上所有以「能力」为核心的练习都存在着这样的情况,但是宏观尺度上长期的练习的确是能够带来很多的改变。
将一个过去的小故事,我记得刚上高一的时候我们英语老师老师,一个小老太太,特别坏。她组织了一场班级内部的小考试,把当年的高考题拿出来让我们做,还骗我们说这是「高级中考题」。让初中毕业生做高考题谁吃得住啊,所以把我们所有人都搞得很痛苦。我记得当时我才考了 91 分,大家刚开始都是这样的,但多练练就会了,高中三年磨下来,我最后不也还是拿了 130 嘛。
考研英语的问题就更鸡掰一点,当年做「考研经验分享」的时候就有很多人问我「英语怎么搞」?我给了一个很粗暴的答——你要做的事情,你把能买到的练习册全都买回来,然后一本一本的全做一遍之后,你的成绩自然就上来了。你也不用管那个题的质量好不好,像是新东方那种烂破底线的题扫一眼阅读内容本身就可以扔了,质量还成的题(比如张剑小黄书)就下手把题坐一坐。我真的都做过,真的有差。
张剑的那本厚的要死的小黄书非常有名。这套书非常好,因为他很厚适合用来防身、里边的题量非常的大,而且它的题质量还没那么好,哪怕大量的刷也不会那么心疼。真题就不能这么遭害嘛,但是模拟题是可以无脑刷的,这本刷完了还有下一本,非常适合用来作为「冲击疗法」的材料。但是雅思就不能这么搞了,因为它没有「海量模拟题」可以用来海巡,基本真题用完了就是用完了,买不到更多题目了,这就会变得相当难搞。
我身边就有很多学生,前 10 篇都没做完就扔在那儿了,都已经上了考场了,买的第一本练习册还是没有做完。这件事情也常见于高三,一本练习册做两道题就扔一边了,毕业的时候扔跳蚤市场卖给下一届学生下一届再做两道题,再往下传。这传家宝是吧 =ω=?
通常来讲任何一本英语练习册如果 2 个月还没有做完,就说明大概率是动力系统出问题了,这个时候请阅读本文第一章的内容~
语法
一个暴论:K 语法书是完全没用的,拿着一道选择题跟你讲「主谓宾定状补」也是没用的。
通常一提语法就「主谓宾定状补」的教学模式搞混了两个概念:「语用能力」和「语言学」。无论是中高考还是考研,考的都是「语用能力」,这和「语言学」有着非常本质的差别:
- 当我们从语用的角度来分析一个「语法错误」的时候,我们会这么做:「你实际上想表达的意思是这样的,但是如果你这么说这句话,他实际表的的意思就会变成那样,这里有一个规律你需要掌握」;
- 当我们从「语言学」的角度来分析一个「语法错误」的时候,我们会这么做:「这句话的句子结构是这样的,这个短语在这个句子里面做这个成分,这个时候这个词作用是 X 语,他和 XX 语法规则不符所以我们不可以这样用」。
实际上我们在讲中文的时候也没有在脑子里面分析每句话的主谓宾定状补,哪怕是语文课也很少有讲这些知识。我们当然可以用「语言学」的技术来解决每一道题,但对于大多数学生来讲这都是不现实的,在缺乏足够多语用经验的情况下,架空支起一个语言学框架会让很多学生无所适从,这也就是为什么我们会在英语课上看到非常荒谬的情况:用「语言学」知识解题目通常只有一部分前段班的学生能听得懂,其他人都在茫然的思考午饭应该吃什么,英语上的「常做常错,常考常新」就是这么来的。
当然我们不能说语法工具书是没有用的,但是使用这些工具书的思路需要改变,通常和某一特定语法话题有关的语用错误积累了一定量之后,再回去翻译法书并修正你表达,这时会有非常好的效果,因为在语法概念下我们已经积累了相当多实际的语用问题,这个时候和语法有关的知识才能构建的起来。
所以这里我更推荐通过写作、积累大量语用错误并且修正的方式来学习语法,而不是单纯的背语法规则。
进阶之路:写作练习
通过「科学堆量」的阅读练习方法,基本上高考英语刷到 120 分、考研英语拿到 70 分以上基本上是没什么问题的(考研英语具体还是要看省份的,这里以全国阅卷最严格的北京为标准)。你可能会说 120 分 或者 70 分好像也没有很高。但是这个分数对于我接触到的大多数学生来讲都够用了,清华北大一共才多少人嘛,北京所有高校叠在一起也没有多少人嘛。不是每个人都需要清华北大,对于很多学生来讲 120 分可能已经是一个很理想的成绩了,但如果你在追求的是更高的成绩的话,我们可能就要探索「应用」层级的只是要求了。
对于英语这门学科,「应用」层级的知识要求就是真实的「语用能力」了。进一步讲,就是「写作」。
 假设你是李华
假设你是李华
高考、中考的时候写作的题目格式非常的明确,形式非常的简单:假设你是李华,请您喵两句 =ω=。写了这么多年你都不知道你在假扮一只狸花猫猫猫是吧~其实在我看来这种水平的题目对于提升整体语用能力来讲难度真的偏低,通过这种题目很难系统性的训练到「各种时态」的使用,也很难覆盖到所有「常见词汇」和「语法结构」。
如果要冲 120 分以上的话,可能还是需要写点高级的东西,不要盯着高考作文题目来练。在这里推荐几个题目的来源:
- 高中教材的课文: 你高中教材的课文就是有标题啊那个那个标题就是命题作文啊,命题作文的题目吗?就直接拿它来写就好了;
- Write & Improve: 剑桥他们出的一套不要钱的课,难度在高考之上,且有明确的梯度可以选,但是比雅思题目要简单。
- 雅思作文: 如果你志向高远,或者真的在准备雅思,那么可以去写雅思的作文题,几个很明确的大类题目是非常适合打磨写作水平和思考能力的。
我们以高中教材为例,事实上每一个单元的那个标题都是非常好的作文题目,我们就可以用它来写命题作文嘛,比如说「Why do we Celebrate festivals?」,这个题目就非常好。考雅思的话,雅思作文的题目本身质量就很高了,比如像:「转基因食品或者基改食物,你的想法是什么,它的好处是什么,它有什么不好的地方?」、或者是「你对胎儿的基因编辑和基因疗法你有什么样的这个看法?」,写一篇二百五十词的作文。
那有可能有人会说,我写不出来怎么办呢?我跟你讲,大家都一样,瞎写咯。第一次都很痛,我刚开始学雅思的时候我也很痛。当时我把我的作文拿给一个批改服务,那个批改服务跟我说你这个东西已经太烂了,我真的是没有办法救你了。啊,要不然我们有个课您看您要不要买个课?我这还有个优惠码哦!
刚开始大家都这样都会有这种挫败感,但是硬写就对了,伟大的现代科技都能帮你凹回来!如果单词不会拼,就根据单词的读音把大概的拼写猜出来,然后硬塞进去,错了没有关系的。再比如说表达方法,如果你觉得某个意思自己表达不出来,那就想办法硬凹,把它糊上去。
第一次写、第二次写的时候百分之百惨不忍睹,但就是去写。写完之后可以用这些工具来处理这篇作文(锵锵~哆啦A梦音效——):
- 用 Grammarly 来查你的语法结构;
- 用 ChatGPT 来帮你做文章润色;
- 用 DeepL Writing 来做单独某一句话的打磨。
这三个东西都不要钱,而且贼好用。
除此之外你或许还需要一个写作方法课,根据你要考什么样的考试,网上都会有一大堆对应的课程。随便任何一套课基本都能解决你的问题。至于怎么挑课反倒是最不重要的。老师的声音你喜欢,OK!这个老师胸大你喜欢,OK! 那个老师长的帅,OK!这个课你看得对上眼,OK!反正就是找这个让你开心的课就行。
比如说我在上的是两套课,一套课叫做雅思之路,另外一套课是 ed:m 在 PPA 上出的这个课。这些课都很不错,买回来了就上呗。
比如说雅思之路,他会教你在写一个作文的时候大致的流程是什么,比如怎么读标题、怎么打框架、怎么做你的写作计划、如何与读者换位思考、如何检查你的作文,他会提醒你要写草稿,最后要对文章做检查。他还给你举了一些例子,不同的人通常会怎样定他们的框架。ed:m 的课切入角度就更加实用一些,他把作文大概分成几个类别,然后告诉你每一个类别对应的你能够用到的词汇是什么。表达每一种意思的时候,你能用到的语法结构是什么,从这里面去学学一会了。
接下来就是把手弄脏的时间啦,开始瞎鸡巴写吧!不管你写成什么样子 ChatGPT 都能帮你凹回来哒!这里给你提供一些很好用的 Prompt:
This is a practice for the IELTS writing test, please list all the mistakes I made and give a list of suggestions to improve the article.
[把你的文章粘到这个位置]
这样她就会开始输出一大堆建议,接下来我们请 ChatGPT 帮你凹文章:
Can you polish the article with the suggestion you give, rephrase every single sentence to make it looks more professional, and get at least 8 marks in IELTS?
请注意这里我加了一句「and get at least 8 marks in IELTS?」,也就是请帮助我在雅思当中得8分。这个8分是很重要的,你给他提供的要求不一样,他输出的范文也会不一样,你可以请她帮你改 6 作文,也可以改 7 分作文或者 8 分作文。具体修作文的标准取决于你当前的语言能力水平。比如说你现在如果是 4.5分 的一个水平,那你可以请 ChatGPT 帮你修成 6 分作文(这里会建议最低修成 6 分作文,修成 5 分作文是没有意义的),
在请 ChatGPT 小姐帮你修作文的时候不太建议「越级打怪」,我曾经尝试让他帮我修一个 9 分版本的文章出来,她也的确照做了,但最后修出来的东西只能说是熟悉又陌生。它依然是我的作文,思路和我的生命经历都是一致的,但是很微妙的这文章我竟然看不懂!这样的范文对我来讲就是「不舒适」的:它对我来讲太难了,我从里面学不到东西。但是他给我修一个 8 分的时候,我就能够从里边提取出来一些我学的会的词汇、一些比较不错的表达方法。因为它是以我们自己写出来的文章为蓝本进行重写的,所以它符合我们的生命经验,只是表达的更加流畅。
ChatGPT 有一个问题是他在修语法错误的时候,给出的诊断不是非常结构化,它不会告诉你每一个语法错误对应的类别是什么,但 Grammarly 可以。所以我建议在 ChatGPT 生成完范文的同时,也用 Grammarly 检查一遍自己文章的语法错误。Grammarly 会拉一个表出来,比如说像「你的动词时态错了」、「你的介词用错了」、「你多加了冠词」等等。我们可以针对每一种语法错误进行整理和学习。这个时候你可以随便翻出来一本压箱底的语法书,或者去 YouTube 上找一些语法教学,来帮助自己理解某一个语法规则,甚至你也可以重新打开 ChatGPT 让她给你讲一些语法知识,比如说我可以这样问 ChatGPT:
The sentence: “Raised concern about its effect on health”, I’m confused about the usage of the preposition, why should I use “effect on” but not “effect to”, “effect of” or “effect for” or “effect about”?
它就会给你一个比较完整的解释:
The preposition “on” is used to indicate that something has an impact or influence on something else. In this sentence, “raised concern about its effect on health” means that there is concern about the impact or influence the effect has on health. “Effect to” would not be appropriate because it does not convey the sense of impact or influence. “Effect of” would suggest that the effect is a result or consequence of something else, rather than having an impact on something. “Effect for” would suggest that there is a benefit for health, which is not what the sentence is trying to convey. “Effect about” is not a commonly used preposition and would not be appropriate in this context.
在这里分享两个我平时常用的分析介词使用的 Prompt:
The word “[你的介系词]” is showing the relationship between the word “[前面的动词]” and “[后面的名词]”, can you explain what kind of relationship the word “about” is trying to express?
你还可以请 ChatGPT 为你解释每一个错误用法具体为什么是错的:
Now, I know the usage of “[错误搭配]”, “[错误搭配]” or “[错误搭配]” or “[错误搭配]” is wrong, can you tell me what does these expressions are trying to express if they are presented?
最后,如果你发现自己写的某个句子特别惨不忍睹,想要做一些修正,那么可以试试 DeepL Writing,比如说我们随便找一句话贴进去:
The market nowadays are increasingly competitive, both companies and employees are facing more stress to survive.
他就会给我们列出一大堆可行的重写:
- Today’s markets are increasingly competitive. Both companies and employees are under more pressure to survive.
- Both companies and employees are under more stress to survive in today’s increasingly competitive markets.
- The market today is becoming more and more competitive and both companies and employees are facing more and more stress to survive.
句子写的越烂,重写的效果越好,我们可以挑一个自己也能写的出来的句子进行学习,久而久之的你就学会了如何写一个靠谱的句子了。
唯独需要提醒的是,Grammarly 有的时候会给出错误的建议,特别是冠词纠正,绝对是有系统性的问题的。所以我会建议如果你觉得哪些纠正看起来很怪,我们可以那句话粘回 ChatGPT 做一个 Cross Validate:
The following sentence’s grammar usage iS wrong:For government, there should be policies to solve the financial problem of these young people. by delaying the loan repayment and setting up relevant subsidies.Instead 0f saying “delaying the loan repayment”, it should be “delaying loan repayment”, there shouldn’t be an article, Can you tell me the reason?
这个时候 ChatGPT 就会给你解释:
The sentence is grammatically correct. The phrase “delaying the loan repayment” is correct as it is referring to a specific type of loan repayment. The definite article “the” is used to refer to a specific noun, in this case is “the loan repayment” is a specific action that government should undertake.If you want to use “delaying loan repayment” it would mean to delaying any kind of loan repayment without specifying which one.lt could be rephrased as “For government, there should be policies to solve the financial problem of these young people by implementing measures such as delaying the repayment of specific loans and providing relevant subsidies”
ChatGPT 会告诉我们,Grammarly 其实改错了,你的写法也是对的,你想表达的意思是什么样的(虽然你自己可能都不知道自己在共三小),Grammarly 想表达的意思是什么,你更想用哪一个语义去表达,可以自己挑一个。他还告诉我们说这句话其实写的有点烂,你其实可以这样说。就像一个温柔的大姐姐一样,手把手教你怎么样去写这个作文,这就是非常好的一个指导。
通过这些在线工具学英语和学校老师不一样,它没有任何次数和时间上的的限制,我们可以无限制的去问他各种各样的问题。除此以外,在向 ChatGPT 提问时,我们可以有一个非常轻松的一个心态,他不会觉得不耐烦,也不会有任何脾气。老师也也要也要就是管管家里的孩子是吧,人家也有生活要过,人家也有卷子要批,人家也要开教研会,人家还要备课,人家有很多事情。你肯定是不能写一篇作文,一句话一句话地去问你的老师,但是在线工具无所谓!反正他就乖巧的坐在那里,你哪怕后半夜发癫想写点作文也可以随时去问他,非常便利。
至此我们已经把整篇作文涉及到的知识点都加工完了,该整理笔记啦!首先要做的是把原来自己写的那坨 Shit 丢掉,把 ChatGPT 批改过的文章工工整整地抄到本子上。这个地方我会推荐用纸笔来写,因为它能强迫我们进行加工。电子笔记没有用,啪唧一下粘到 Word 里面没有灵魂,也记不住。
 写作笔记
写作笔记
在抄笔记的时候我一般习惯写单面,右边是 ChatGPT 改出来的文章,左面是各种注记,主要用来比较 ChatGPT 的改动和原本自己写的内容分别是什么。通过这个过程我们可以熟悉一些更加高级的表达方式,还有一些虽然自己能看得懂但是写不出来的内容。
每篇文章后面通常还需要整理出来一个词汇表,把自己瞎机霸猜但是猜错的词都拉出来方便日后背诵拼写。这个单词表才是真正有用的单词表,因为你在写作的时候真的能想起来用这些词,如果能拼对的话,他们就是最有价值的语料资源。
接下来,所有 Grammarly 筛出来的语法错误最好也整理出来一个列表,按照语法错误的类型做一个简单的归类,最后系统性的学习对应的语法知识。
最后,对于每一次写作练习,至多整理一个重点学习内容,比如我的这个例子里面整理出了若干个表达「某个话题引起了许多争议」的方法。至多挑一个来整理是很有必要的,整理太多就会有心理负担,再反复抉择之后挑出一个最重要的,挑选的过程中就已经是在强化记忆了,最后整理出来的哪一个知识一定是印象最深刻的,日后查阅也会更方便。
我们在不停写作、润色、整理的个过程,实际上就是在重新写一本属于你自己的教材的一个过程。英语教材的你虽然也很有用,但大多数情况下用的是他后面那个词汇表,前面那个课文真的不一定有很大用处,因为它和你的生命经历不相符,但是你自己写的这篇文章和你的生命经历是相符的,他就是按照你的思路来的,阅读和学习起来认知负担就会相对小一些。这样我们能够更加容易地从这些语料当中学到新的知识,所以这个东西它更加适合你。
这份笔记的结构跟教材是一样的,它有一篇大课文,包含了各式各样地道的表达方法,也有语法的教学和词汇表。但不同的是,这本教材的每一篇作文都是为你量身打造的:因为这东西就是你写的,你可以在一个比较舒适的环境当中逐步提升。通过这种方式不断练习的过程,实际上就是把每一个词汇,每一个语法概念,每一个语用的这个元素重新编织成概念网络的一个过程过程,其实它考验的还是一个归纳整理的一个能力,只不过外在的形式不一样而已。
演绎推理
接下来我们来看数学和物理这两个科目,我必须非常坦白的讲,这个我不行。
我的数学和物理成绩是非常非常烂的,如果今天我教你数学要怎么学,我的高中老师绝对会笑到拍大腿,我的物理成绩也是没有一次及格的,所以我不能教你怎么学这个东西,但是我可以给你提供一些思路还有我自己的经验和感受。
数学
我们可以把每一道数学题抽象成一个这样的结构:
 数学题的抽象结构
数学题的抽象结构
在这张图里面,左面圆圈是题目给我们的条件,右面的圆圈代表最终我们要得出来的结论,这个过程实际上就是利用自己手里的知识和题目当中给的条件来构建一个完整的逻辑链条。决定一个数学题目难度的决定因素有两个:一个是它使用的知识究竟有多隐晦或者知识量有多大,另外一个便是逻辑链条的长度(一共有多少个步骤要进行推演)和复杂度(需要处理多少个逻辑分支)。下面这个小视频演示了逻辑推理的抽象过程:
 数学题的抽象结构
数学题的抽象结构
我们拿出一个条件,和一个我们既有的知识,推断出一个推论,再用这个推论和其它条件、知识继续推断直到得到我们需要的结论。这一切看起来很美好但实际上很多考生在解题时的感受通常是这样的:
 实际上的情况
实际上的情况
第一部通常是很简单的,找到最浅显的条件和公式,拼一下就能得出一个结论了。但是推第二步的时候前面是做什么,大概大概就忘记了,或许这一步需要的知识可能也不是很懂(就是所谓的这个工具掌握的不够熟练),非常勉强的把第二步推下去了。推第三步的时候,前面所有的东西就全都全都忘了,这个地方推的也比较薄弱。现在开始,OK,所有的条件,所有的知识,所有的这个推论全都在天上闪,但是你一个都抓不住,逻辑链条已经维持不住了,根本不知道自己在做什么,然后就稀里糊涂的就把这个东西给推下去了。
这里有一个很重要的一个感受就是你发现所有东西都在天上闪,但是你一个都把握不住,最后稀里哗啦的敷衍一下,Q.E.D!
注意能力
出现这个问题主要有两个原因:一方面有手艺活的部分,知识掌握的不够扎实的话,提取「工具」的过程就会变得不够「流畅」,通常为了解决这个问题刷题就可以了。
但另外一方面很重要的是「注意能力」,那个闪的感觉、那个「把握不住」的感觉,实际上就是注意力没有维持住。如果「注意能力」比较欠缺的话,在做题时就会产生一种一种「高度疲劳」、「无法集中」的感觉。这个时候再做题很容易就放弃。注意能力出问题的话,很多其他科目也会跟着出问题,比如语文的文言文阅读、长句子的书写、化学方程式的配平、平时背单词背课文、生物的基因型推断、英语的语法类型推断、还有最简单的数值计算全部都会出问题。
我们以语文的「文言文阅读」为例,这是一个我从高考题里边摘出来的一篇练习题:
孟尝君之赵,谓赵王曰:“文愿借兵以救魏。”赵王曰:“寡人不能。”孟尝君曰:“夫敢借兵者,以忠王也。”王曰:“可得闻乎?”孟尝君曰:“夫赵之兵非能强于魏之兵,魏之兵非能弱于赵也。然而赵之地不岁危,而民不岁死;而魏之地岁危而民岁死者,何也?以其西为赵蔽也。
比如说一道题和这一个一个句子或者两个句子有关,我们需要理解这两句话的意思并且形成一个推论,但我们在读这句话的时候,读着读着后面的话就不知道前面的东西是什么了,再往后读一读前面的东西又丢了,最后一个句子都没有读出来,所有东西都已经散掉了,这个时候题目就会做不出来。
有的读者可能会问那为什么我能处理「现代文」却不能处理「古文」阅读?一方面可能是注解背的不够熟练,但是另外一方面就很有可能是加工能力不太够,因为对于古文来讲每一个字的加工都是非常非常消耗认知资源的,它需要更高度水平的注意力才能处理。但有些考生的注意水平不够高,一旦认知资源不够用了,注意力维持不住了的话,就很有可能出现一句话都加工不完整的情况。一句话都加工不完整的话,你对它的语义就没有理解。做题的时候就像一个傻子一样,啊吧啊吧啊吧啊吧啊吧啊吧啊吧啊吧啊吧什么都看不懂,考试分数就不会高。
事实上注意能力严重不足的考生在处理现代文的时候也有可能会出现问题,通常临床上会将其称为「阅读障碍」,是一个非常热门的研究领域,感兴趣的朋友们也可以读一读相关的文献研究。
不光是考试,这样学生平时在生活上面可能也会体现出来某种特征,囧星人曾经做过一个视频,在这里我们把它文字化(想看视频版本或者语音版本请从文章开头的地方找访问链接哦!):
明天截稿,我现在要写剧本的哦!哇猫咪好可爱,他是不是饿了,到吃饭时间没天哪工作好乱,我刚才整理一下。我有点想喝什么打开冰箱看看好了!啊,该把这样的衣服收回来了。Hmmmm… 我刚才到底想干什么?
这样的人经常会被冠以这个人「很马虎」,「丢三落四」,「很浮躁」。但这些因素都是「人格因素」归因:是这个人不好,因为它有什么什么样的特质。但一旦归因到人格,这个事情就很没救了,唯一的解法就是:噔噔噔噔!
 人生重来枪
人生重来枪
人生重来枪!你这辈子重来吧!哈哈!但这是有可能的吗?当然不。
所以我们需要把它归因到一些更加切实可行的因素上,「注意力」或「注意能力」就是一个非常切实可行的归因。你解决「注意力」好,成绩就高,这件事情就会变得很好操作。具体要解决这个问题呢?思路是一样的:难度降级。
一些比较简单的办法,比如说抄写数字(这个我们在之前的文章当中有介绍过),通过螺旋花圈写数字的方式,去体会「集中注意力」是一个什么样的感觉。这和临床治疗当中的情绪控制疗法比较像,通过不断体会集中注意力的感觉来习得「集中注意力」是如何操作的,慢慢学一学就学会了。这类任务足够简单,它不会像数学题一样,把各种各样的公式、和各种其他认知过程一起给灌到任务里,它就是非常纯粹的注意力练习,每天都做这种联系,慢慢的可能就学会了。
 一种改善注意力稳定性的方法
一种改善注意力稳定性的方法
你可能会觉得这东西好无聊啊,有没有什么更好玩的?当然有!比如说围棋就是一个非常好的项目,国际象棋、中国象棋也都很适合用来练习注意力,在下棋的过程中是会要求你的注意力能够高度的集中去处理这个整个棋局变化的。但五子棋、飞行棋、跳棋这种相对来讲就没有用。我们可以找一个软件,调一个适合自己的难度电脑下。亦或者也可以用在线平台,在网上和其他人下。
如果觉得没什么动力的话,看看棋灵王、研究研究 Alpha Go,看看哈利波特,可能就会觉得这个东西很帅,最后就产生兴趣了。
但是如果你发现这个事情真的很严重,哪怕做的这些练习,依然没有办法,并且觉得好痛苦,那我会比较推荐你去医院进行 ADHD 的 诊断,我先前做过一期节目讲和 ADHD 有关的知识,推荐对这个话题感兴趣的朋友去听一下:
在这里唯一需要叮嘱的是,根据自己的接受情况选择处理方法,可以通过一些认知训练的技术来不断提升注意能力和阅读能力,也可以根据医嘱服用药物来改善情况。具体情况要看自己能接受什么样的方案,不要太过勉强自己。不解决也是没有关系的,学会与之和谐共处同样是一种方法。
手艺活:错题本
接下来我们再来看和技能熟练度有关的部分,对于数学这一个科目实际上我会倾向于认为「错题本」能够起到些许作用。我建议用活页本来整理题目,每一页只整理一道题。无论是选择题、填空题,都整理成简答题的形式,正面把题目抄下来背面把完整的推导流程记住。
比较忌讳的是选择题就把四个选项都抄下来,每次练的时候也就只看着选项做回答。其实 ABCD 看一遍就能记住了,能选对也不意味着这题就会做了,所以抄选项的用处不大。
就是把把思维过程记录下来了,然后把解题过程记录下来,能够确保你下次看这个错题本重新做的时候,能够把这个题做下来。然后很重要的一点是在整理错题的时候来想办法回忆当时自己是做到哪里卡住了,当时自己是怎么想的,要把这个思维过程形成记录,然后你会发现自己什么地方出问题了。在记录的过程中我会推荐各位着重回想自己究竟是哪个地方卡住了,当时自己是怎么想的,尽可能多的把整个解题过程回访出来,这样有助于我们总结出问题真正问题的核心。
活页笔记本的好处是,我们可以根据题目的类型重新的把内容打散了重新进行组织,一般的本子做这件事情相对来讲就会麻烦一些。
关于课后班
相当多的家长会陷入一种非常诡异的逻辑中:孩子成绩不好怎么办?课后班!更多的课后班!もっと!もっと!もっと!更多、更多、更多的课后班!天天学,每天学到后半夜!对于这种家长我只能竖起中指。
大多数课后班基本都是没什么用的,特别是补全科更是完全浪费心力。道理非常的简单,上课你老师怎么教,期中期末复习还是怎么教,课后班老师还是怎么教。你觉得教一遍、教两遍、教三遍都学不会,教四遍就能学会吗?学不会的。一定还是底下有什么东西出问题了,只盯着上面的成绩说事很大程度上只是一种刻舟求剑的行为。
我曾经遇到过一个家长,小两口异常焦虑,从他们的谈吐和神情当中能够感受到一种巨大的压力,甚至那个家长会吃着吃着饭,就得哭出来。孩子下班之后,家里开车杀到学校门口把孩子接上车,然后在车上吃饭,一个课后班一个课后班得跑。孩子半夜回家写作业,写完作业之后简单睡几个小时第二天再去学校折腾。一年到头都是这样跑,寒假暑假都是这样折腾的。看到那个孩子,我都会觉得好可怜。很可爱的一个小女生,白白净净的,眼睛特别大,性格很活泼,但是你能从他的笑容当中看到一丝苦涩在里边——你能够看到一些不属于他这个年纪的应有的疲劳和忧愁。
这样做实际上是完全没有用的,这对父母实际上只是在不停的证明自己得无能,没有能力去提供一个良好的社会支持系统,甚至他自己在破坏这个社会支持系统。他们自己不能控制自己的焦虑,这种庞大的负面情感盘旋在整个家庭的上空带来了庞大的不幸。他们也不能和自己的孩子共情:这个时候那个孩子其实需要的不是这些,他可能也不一定是那么高的一个分数,这个时候这孩子可能需要家长抱他一下,说一句你真的辛苦了,我们一起来想办法。
我们的教育常常鼓励孩子像父母说一句「辛苦了」,可是谁不辛苦呢,这个时代的孩子也挺辛苦的,可是鲜有人告诉孩子,有人知道他们有多苦。
这个小孩子需要的是大人和她们手拉手去解决实际存在的问题,至少在家里边跟孩子一边下围棋一遍喝喝果汁聊聊天,还开心一点。有的父母可能觉得这些东西没有用,的确表面上没什么用,但按照我们之前讲的整个模型体系,其实它起的作用要比上万元的补习班有用的多。
小结
这就是一个和最终成绩有关的完整模型。能力为度和情绪维度套起来最后就会表现为外在的分数。
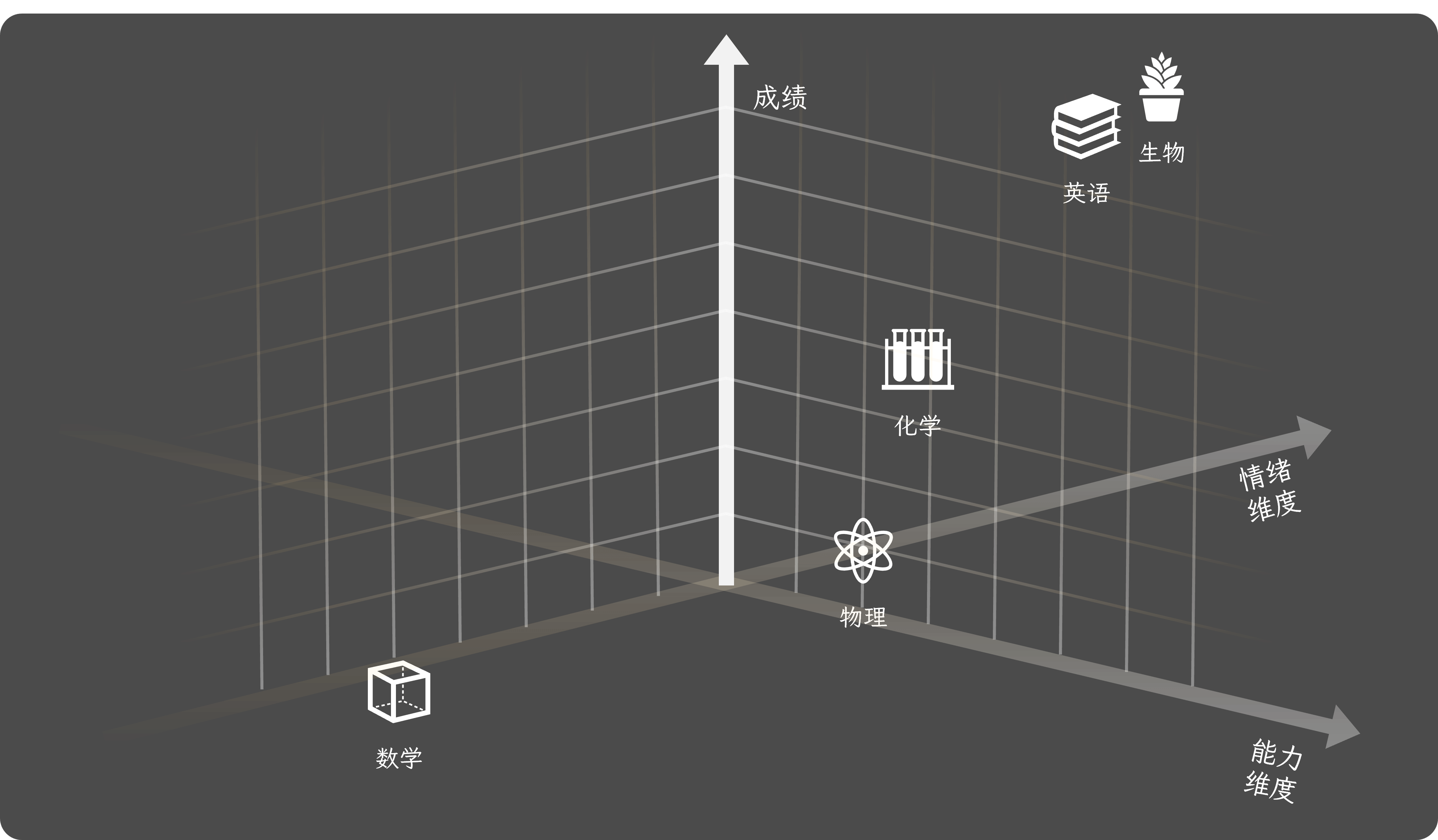 与「归纳总结」和「演绎推理」有关的能力模型
与「归纳总结」和「演绎推理」有关的能力模型
上面整个章节我们讨论的其实就是与「归纳总结」和「演绎推理」有关的能力模型,它最终会外显的表现为考生在考试当中所得得分数。分数是一个很容易被看见的事物,但能力不是。如果我们只针对成绩这件事情来处理的话,很容易就会走歪。
 与最终成绩有关的模型
与最终成绩有关的模型
整个讨论的核心的思路就是「难度降级」,把所有学习任务的难度都降到一个恰巧在舒适圈之外的难度,在进行持续的练习,这样能力才会有逐步的提升。通常来说学习上的困难可以被理解为一个台阶卖不上去了,迈不上去的原因是对于这个考生来讲,这步楼梯太高了。太高了怎么办?我们可以找块砖头垫一下,先走半个台阶,再走下面的台阶。
这就像找一只藏獒和一只柯基,一起爬高楼大厦,藏獒当然可以一步、一步地跨上,但是柯基上不去。那你觉得柯基有问题吗?柯基当然没有问题!你看它那么可爱!映射到现实世界也是一样的,有人一步迈不上去,不能说你人格怎么样,或者说它就是笨。找到真的迈不上去的台阶在哪里(映射到哪个能力上),给予情感支持并且一块砖头(合适的方法),大家都是能迈得过去的。
在前面的文章中,我们提到了很多种方法,但是这些方法不一定适合所有人,每个人都有自己的生命脉络,对应的一定会有不同的学习方式,探索这些学习方式并且去践行他们才是有效教育任务的核心议题。
语文
这个时候你可能会问,诶,怎么没有语文?
我,我也想知道语文是怎么回事啊 (つд⊂)。哪怕大学毕业、研究生毕业,学历穿越了两个师范大学,我依然没能参透语文这个学科究竟是在学三小。所以长久以来语文这一科对我来讲一直都是科目 X。我直到我出了社会,工作了两三年之后才逐渐形成了对这个科目的理解。
语文这一课如果我们对它进行一个解构,可以分成大概四块:「语言能力」、「应试技巧」、「书法技巧」和「思考能力」。
通常来讲,一个人的语文能力都不会差到哪里去,跟老外比大家的语言能力都不会差多少。另外一方面,考试技巧其实也没什么可以多说的,那些东西上课老师都教过很多次。有听就有懂,没听就没懂,也没什么解决和提高的空间。
但接下来的两件事情就有很多可以说的了,我们先提「书法」。
书法
平常我们说「书法」这个词基本上就是在说你写的字好不好看。语文这一科是个非常吃这方面技巧的学科,字写得「好看」是很唬人的,少会有十分至二十分的加成。光是把写字的问题处理好就能解决很大的问题了。
但一提到书法,可能就会问一些很世俗的问题:用铅笔练字还是钢笔练字好呀~总有人说碳素笔不练字呀~钢笔要用美术尖才更练字呀~你要用什么纸来练呀~A4纸还是什么专用纸呀~练行书、练楷体、练隶书还是艺术体呀~我买谁的字帖比较合适呀~
我有一个朋友,有一句话讲的非常好:「当代大众审美对于书法的认知,基本上等于和印刷体写的像不像」。我觉得她说的非常对。我们要搞清楚应试教育的场景下练字的目的是什么:我们要做的事情不是写出艺术风格,而是讨好扫描仪。真的很有艺术风格的书法作品不一定是非常「好看」的,也不一定符合大众审美。如果要讨好扫描仪的话,事情就会变得比较简单了:「方正书宋」、「方正楷体」。如果你没有听说过这两种字体的话,他们就是印在你教材上面的印刷体。横写的细、竖写的粗、转角记得顿笔,就照着你教材上面的印刷体练基本上就可以了。也不太需要买太多字帖。有一些字就算放到白纸上好看,放到扫描仪上面扫出来也不一定好看。
讲一个例子,我在上初中的时候,有一个美术老师是书法艺术家,写的字非常奇怪,他写的不是方块字而是扇形的字,很有自己的艺术风格。她就在学校里面狂推自己的字体,希望让更多学生去学习她的书法风格。有个班主任就非常的有病,强迫他们班所有的学生都写这个字,最后的结果是他们班的学生写的字都好奇怪。真的没有必要,浪费时间浪费精力。
所以在这里给出一个结论,对于在校学生来讲,如果单纯为了考试能拿高分而练字:碳素笔、新闻纸、印刷体。得 100、110 分左右基本没有问题。对于很多人来讲,语文 100 分以上已经非常够用了。真的想练字的话还是推荐去写毛笔字。硬笔书法这个事情,是庞中华近几十年来带起来的,早些年「硬笔书法」这个概念是不存在的。所以如果真的去追寻哪个「正统」,不如去买几根毛笔玩一玩。然后你过年的时候人家门上都写的「福」都是打印的,你还能自己写一个,不也挺好。但是这些东西对应试教育来讲作用不是很大,「书法艺术」和「应试书法」在门类上属于两个概念。考试的时候唯一需要记住的是淡定、冷静、一笔一划慢慢写。如果整篇卷面都是规整的「蝇头小楷」通常分数不会特别差。如果考试的时候情绪慌了,开始狂草了,那基本就完蛋了。
其实这件事情也比较好理解,六月份三伏天,一大堆老师们在机房里边,可能空调风扇还不太好使,充满着汗臭味。电脑屏幕上一篇、一篇、一篇、一篇、一篇、一篇的烂字作文,然后啪突然出来一篇字还写得不错的文章,印象分就会很高。通常阅卷的时候都会先给一个大致的印象分然后再来上修和下修分数。字写的好不好看很影响这个印象分,结果就是在很大程度上决定了这一篇文章最后能拿多少分,或者你整个语文成绩是多少。
淡定冷静,慢慢写写,印刷体,一点点练,最后都会有好结果的。
思考能力
接下来这个话题就会变得比较奥妙了,思考能力是怎么建立起来的呢?在这里我给出来的答案是:「哲♂学」。
Deep♂Dark♂Fantasy?Nah,不是这种东西!哲学是什么?罗素对它定义是这样的:
哲学,就我对这个词的理解来说,乃是某种介乎神学与科学之间的东西。它和神学一样,包含着人类对于那些迄今仍为科学知识所不能肯定之事物的思考;但它又像科学一样,是诉之于人类的理性而不是诉之于权威的,不论是传统的权威还是启示的权威。一切确切的知识都属于科学;一切涉及超乎确切知识之外的教条都属于神学。但介乎神学与科学之间还有一片受到双方攻击的无人之域,這片无人之域就是哲学。
你对「哲学」这个概念的理解可能和上面这句话很像:
「三小叮当——」
高大上又玄学,深奥又渺茫,完全不知道那是啥玩意反正跟我没啥关系。
但其实「哲学」这个概念实际上还是比较贴近生活的,对于普罗大众来讲,「哲学」这一概念比较接近于「如何思考」:就是不断的题不断地问「为什么」和「是什么」。 不断的问问题,这个时候你可能会觉得困惑:我们要问什么样的问题呢?在这里我可以给你提供一个小型的框架:「了解自己」、「了解身边的人」、「了解更广泛的世界」。
了解自己
「探索自我、悦纳自我」实际上是一个非常宏大的话题,但我们可以从一些非常简单的点入手:了解自己的情绪情感、了解自己的认知过程、了解自己的个人喜好,让「自我」的概念更加立体。
个人喜好
我们先来看最简单的个人喜好:你喜欢什么?你不喜欢什么?
这个时候很多人可能就会说「我喜欢打游戏!」,之后我来给你表演一下,这个社会刻板印象怎么建立起来的:
网瘾!只要打游戏就一定网瘾,然后就电子海洛因是吧。跟网瘾有关的一大堆破事儿就起来了,什么谈恋爱啊、翘课啊共称什么校园三大罪恶是吧。什么不好好学习,天天就知道翻墙逃学打游戏,然后来一堆警告处分,其实搞这些都无助于解决问题,更多的只是用更多的道德枷锁压抑学生的欲望和本能,压抑久了是会炸掉的。
一般情况下,「游戏成瘾」不停一把一把开黑的情况,一般潜藏的内在逻辑是学生在校园环境当中缺乏「成就感」、缺乏「认同感」,甚至是缺乏「安全感」。难以自控的不停开黑,背后的意义很有可能是学生需要一种快速获得积极反馈的一个一种方式。只有通过这种病态式地汲取心理资源的方式,他才能够维持自己的日常生活。把那些外在原因掐了之后,内生出来的焦虑就会赤裸的暴露出来,事情就会变得更加难办。
游戏其实是个好东西,我不知道为什么政策宣传会把「电子游戏」比作「电子海洛因」,并且污名化整个产业和这个产业的终端受众——玩家。对于那种商业攻击性特别强的「商业网游」来讲,施加适当的限制当然没有问题,但是如果把它泛化到整个「游戏产业」,这个就很明显是错误的。
事实上有很多非常优秀的游戏作品可以加深我们对于这个世界的理解:
 一些还不错的游戏
一些还不错的游戏
从这张图你基本上就能看出我的游戏品味是啥样的了(肝佬),一个 P5S 100 小时就出去了,一个八方旅人可能 100 小时又出去了,甚至最终 boss 还没打。有很非常棒的游戏都能给玩家提供一个理解这个世界的切角,它可以帮助我们更好的理解这个社会的运转机制、反思和探索周遭的生活。这些切角就是一个所谓的「抓手」(哎呀,互联网黑话就来了)。
从这个角度来看游戏也可以是是一个非常好的媒介。以游戏产业为例,我们有很多优秀的游戏媒体和研究者,他们真的会把「游戏」当成一个学问去研究和报道,他们向社会大众传播相当丰富的知识和见解。
有一本书我觉得非常好,叫《游戏改变世界》,他介绍了「游戏化」这个概念,通过游戏化的方式可以重新塑造各种各样的行业,比如说教育游戏化,也可以重新塑造我们的生活。
实际上「游戏」和很多概念都能勾连在一起,比如宗教、历史、哲学、心理学、艺术、文化、教育、设计。非常著名的故事,育碧的「刺客信条」和「历史」、「艺术」的关联的就非常好,人家做的真的是非常考究,在玩这些游戏的时候很多知识和文化都能潜移默化的学习到。
很多时候整个教育系统过度抵制游戏,导致我们难以从中挖掘出更多的价值,最后整个系统就停留在了「玩」和「体验」这个层次上。当然我们不能说「体验」不好,就像学校寒暑假留作业做「科学研究」,有学生把一个鸡蛋扔在醋里边,鸡蛋壳变软了,那很好玩,当然很好。但是如果只停留在这里的话就会变得非常可惜。
综述
这些「可惜」的核心是:我们没有充分利用过往的那些「体验」,向其进行「提问」的动作,没有这个动作也就没有深入向下挖掘的可能性。深入挖掘一件事物的方式有很多,玩「维基百科大探险」也可以是一种方法,但是在这里我提出一个更加容易形成「积累」的方式:针对我们感兴趣的话题写「综述」。
找一个感兴趣的话题,想尽办法收集各种自己对这个话题产生「好奇」的点,网上有很多、很多的资料,有些是书,有些是视频,有些只是一条简短的「推特」,我们可以把这些林林总总的信息全都剪碎,重新组织成你自己喜欢的架构和理解,每个人对一个事物的理解和态度都是独一无二的,探索这个「架构」的过程就是理解这个世界、形成丰富人生阅历的过程。一旦形成了对于周遭事物的理解,关于「自我」的概念就会立体,我们通过这些「探索」真正知道了「我喜欢这个东西是什么」、「我为什么喜欢这些东西」、「我喜欢他究竟喜欢在哪里」了,这样我们就完成了一次「自我探索」。
当代社会从「如何套取富婆欢心」到「母猪的产后护理」。甚至到如何鉴赏 A 片、怎么样去嫖娼,这些林林总总的事情都是有学问的。
 那些奇怪的专业
那些奇怪的专业
有一些事情看起来的确是非常的荒谬,这是一个叫「中指通」的台湾人,他专门做 A 片鉴赏,因为「散播欢乐散播爱」而为人津津乐道。因为有很丰富的「风俗经验」所以甚至开了课教大家怎么科学的去日本嫖妓。这个时候你可能会觉得,「世风日下、道德沦丧,应当抵制!」,但人性是非常真实的,这套课程一上线就卖爆了。如果我们用一个传统的道德观念去套它,就会觉得这件事情很难理解。但它的确也是一门生意,这个人因为这套课程赚翻嘞!大家可能会出于种种目的购买这套课,比如说好奇,亦或者是寻求刺激。这些人不一定真的会去日本亲身体验「性产业」。
这个时候你可能会问「A 片有什么求知欲」,但 A 片里面也有很多知识啊,和生物学、生理构造有关的,和摄像摄影有关的,和道德伦理有关的,这些都是都都是知识呀。很明显这里核心的重点是我们如何从这些外在的表象当中挖掘出深入的内容。围绕着我们当代生活所形成的一切,一定都会有其内部的门门道道,通过去挖掘这些知识,我们就会会形成一个对于世界的理解,这些东西可以拯救那些贫瘠的心灵。
我们平时在写作文的时候常常会遇到这样的问题:写不出来呀,什么都写不出来,就一直在空耗着,只能拉出一大堆的大道理。这其中真正的核心原因其实是考生没有形成对这个世界的深入理解。实际上写「综述」就是一个非常好的去深入挖掘的过程,这就是一种对思维的磨练和对自我的探索。
空谈无用,实干兴邦
大道理谁都懂嘛,但是大道理不能说服任何人,因为道理是一个结果,道理不是一个过程,只有经历那个过程的时候,最后那个道理才是有价值的,才能凝练成智慧,这个研究就是探索的这个过程。
所以说看一个电影然后写那个「观后感」啊,不会让你的能力变强。语文老师逼着学生妹提案写练笔,那个会带来非常微量的能力提升,但其实也没有办法让一个学生的写作能力提升很多。
感恩操、给父母洗脚、什么给家里写一封信,那个不会让你更爱你的父母那唱感恩的心,爱的人还是爱,不爱的人还是不爱。不是每一个人都爱他的父母。传统的孝道伦理只会让那些身处不幸家庭的人更加迷茫。就你爱的人,还是爱不爱的人还是不爱你,不喜欢的东西就是没有感悟,就是写不出来那个东西就是写不出来,他就应该写不出来,写的出来才怪了呀。
相同的道理,逼着学生看那些他们根本不喜欢的书,还要做读书笔记,还要做读书月之类的活动,校长在「国旗下讲话」的时候夸夸其谈地说「多读书、读好书」,都是没什么用的,没有动机,没有探求的欲望,读书就只是个形式,那个是没有什么用处的。
情绪情感
接下来我们再来看看和情绪情感情有关的话题。事实上亚洲文化并不鼓励个体表达自己的情绪情感,在你尝试对这些内生的情感进行表达的时候,通常都会受到某种「惩罚」,因此会形成一种「压抑」的氛围。事实上我们的大多数「鲜明的记忆」都是以某种「情绪」为核心的,但是我们并不清楚那些记忆对自己来讲究竟意味着什么,这组织我们更加深入的了解自己。我的咨询师推荐我使用「情绪轮」这样的一个工具来进行自我探索,这种技术非常的有趣,我也推荐你试试:
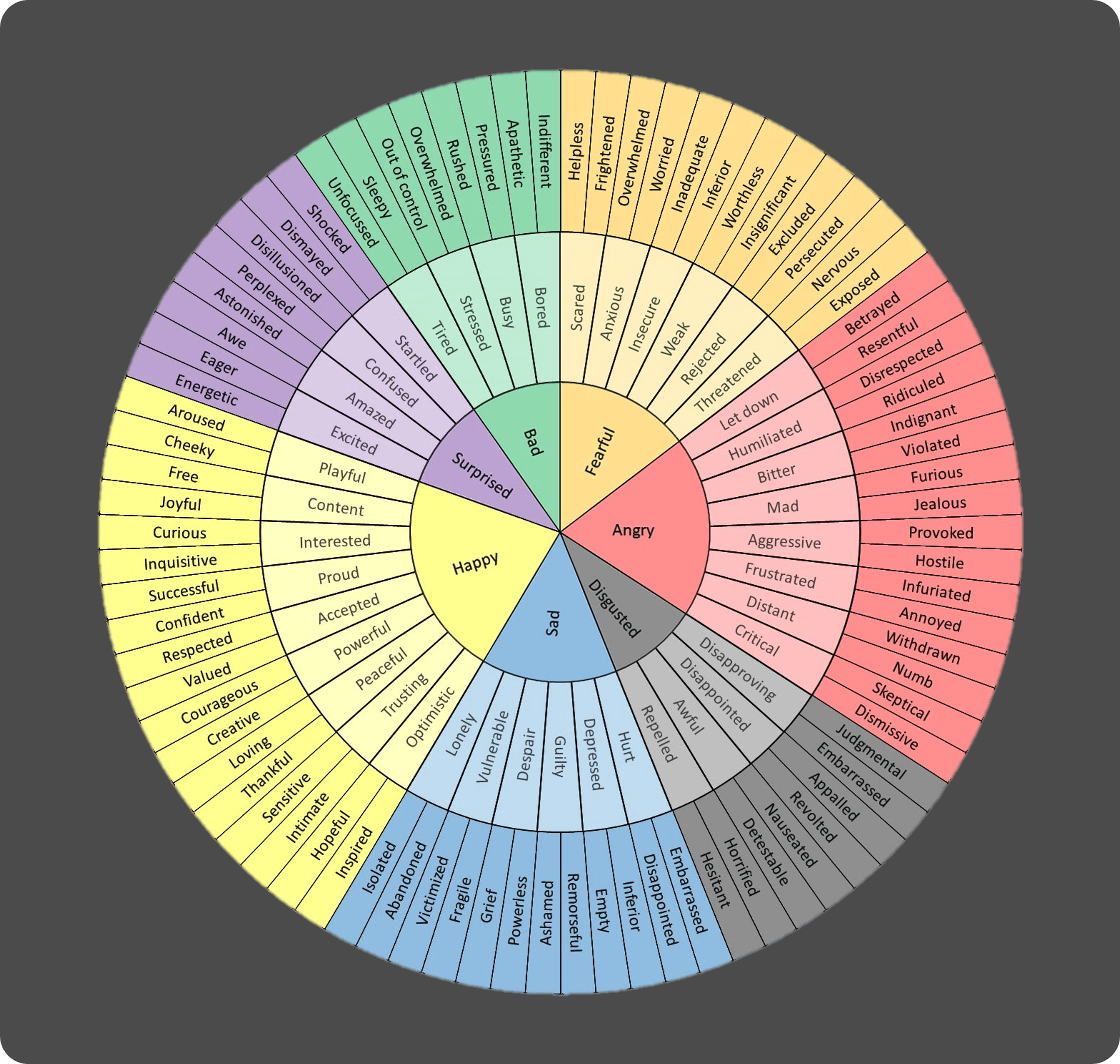 情绪轮
情绪轮
在面对一件情绪激烈的事情时,我们可以通过这个轮盘明确自己在经历的「情绪」究竟是什么,进而更好的理解自己和表达自己,这是了解自己情绪情感的一个很好的起点。
如果我问你什么是愤怒? 生气嘛,对吧!然后紧接着可能就冒出来了一些「励志小语」、「名人名言」、「心灵鸡汤」。什么木头上钉了几根钉子,钉子拔下来了,孔还留在那里,你造成的伤害怎么怎么样?你通过这一个一个的心灵鸡汤产那个悟出来了什么什么人生大道理,从此之后你就不愤怒了吗?
不会,你只会更迷茫,你会更自责,因为你没有符合这个世界上面的纲常伦理。其实「愤怒」不是坏事,失控的愤怒才是坏事,我们要做的时它变得可控的。那些励志小语、那些大道理都是一个「抽象出来的荒谬玩意」:
有没有觉得这玩意很荒谬?的确,这件事情它就是这么荒谬。那个小寓言,那些名人名言,那些励志话语和这个东西,和这个看起来非常欠揍的小视频在本质上没有任何区别,只是这个看起来更加的 Drama 一些。哪怕看一千个、看一万个,人对自己的理解也不会有任何实质的变化,只是会增加越来越多的道德枷锁让人越来越压抑罢了。
更有意义的练习是反思每一个情绪对应的当下的主观感受究竟是怎样的。比如说「愤怒」,我们在愤怒的时候意识是狭窄的,你会觉得很上头你甚至脸都是麻的,你的心跳在变快,你的全身都很热,我们不断的回忆、咀嚼和理解这些情绪感受的过程就是「自我探索」的过程。
我们还可以去反思自己为什么会愤怒。有的读者可能会非常简单的回答这个问题:「因为他惹到我了呀」。那不是「我」为什么会愤怒的原因,他是外在性的归因不是内生性的探索。在进行和「我」有关的探索时,起点一定自己的「生命经验」,是因为这件事情让自己回忆起了「不好的事情」了吗?还是让你觉得自己受到了不公平的对待?
当我们进行这些探索的时候一定会遇到一些「结」和一些「困惑」,那个困惑的点就是能够把认知「展开」的一个点。
这个过程有一个非常高大上的名字,叫做「内观」。内观的过程实际上就是对自己情绪情感理解逐渐丰富的过程,只有对自己的认知是丰满的、立体的时候,我们才能够以自己的生命脉络为模板去理解他人,形成共情,这是人类社会化过程当中非常重要的一环。
那些性格看起来很怪、「很不合群」、很难相处、社会性很差的人通常对自己的情绪情感理解也是单薄的。有的家长可能会抱怨孩子为什么不合群,会说教:「你要合群呀!」。只是去讲个大道理,其实一点用都没有啊,重要的是向下挖,建立一个和人有关的更加立体的形象才是有用的。
有了这个基础模型,个体才能继续理解人与他人之间的关系,人与社会之间的关系。这个过程实际上就是「公民教育」的核心概念。「公民教育」可以帮助我们每一个人形成自己的一个观点,对于这个世界的理解,会形成一个价值体系,会形成一个前进的方向。每个人靠着自我探索形成的那一个方向,所施加的一点点力,最终会形成一个庞大的洪流,把这个社会引向一个更好的方向上去。
 公民教育体系
公民教育体系
终极价值
接下来我们要回答最后的问题了,我们通过公民教育的系统形成了一个对于自己的理解,通过探索字节的好恶也形成了一个完整的价值体系,这个价值体系最后决定我们每个人究竟会去向何方,达成什么样的个人成就。
价值体系这个词是很有趣的,它牵扯到了「价值观」这样的一个概念。价值观这个故弄玄虚的词翻译成大白话的话就是:「究竟什么对自己来说才是重要的」。再把它说的直白一点:「我们理想的生活面貌是什么样的」?
我们高一的班主任曾经开过一次班会,然跟我们去讨论自己未来的理想,和未来生活的面貌。我们班的同学做出的回答都非常有想象力:「我想要一个几千平米的大 house」、「我想去造火箭」、「我想克隆一个地球」。但这些实际上不是「对美好生活的想象」,这个东西叫做「意淫」。
在我所归纳出的整个框架下,「对美好生活的一个想像」应该是一个切实可行的目标,这样的一个目标才是「真实存在」的。它建筑在我们对于生活的理解之上,这种生活不一定是那种波澜壮阔的模样,也有可能非常朴实平庸。
我高中所念的那个班级是一个中段班,什么样的学生都有,大家踏入社会之后,也进入了形形色色的产业。我们高中的数学课代表成绩一般,大学上了一半不念了,养猪去了,人家过得也挺乐呵的。我们班高中的学委,特别可爱的一个小胖子,问他啥他都会,特别的爱吃,每次我打开饭盒的时候,他都会从里面夹两块肉出去,我饭盒里面的什么菜都是他最爱吃的菜,真的很好玩。因为他特别喜欢吃的个性,就去学食品科学了,现在是一个博士,也很厉害。我们班班长学习成绩不好,中后段的学生,后来人家开飞机去了,赚的也挺多的呀。
所以究竟什么样的成绩是够用的,我们究竟想要的是什么?那个想象越切实可行,越具象化,往往一个考生的动力就会越强。
前一段时间我弟弟在考教师职业资格证,他学体育的想当体育老师,这个证他怎么考都考不下来。我妈就问我说怎么办,我的回答相当的冷血:「你管他干嘛,没考下来就是不想考,那不是他理想的生活呀。教师资格证那种水平的东西,真的想考自然是能考到的」。
「打牌」
我经常会这样比喻,我们的生活实际上就是一个巨大的牌局。在成年之前,我们的学校、我们的家庭会给我们各种各样的手牌。它们可能是一个不幸的家庭、可能是尚且富裕的财富、甚至你很会做菜「厨艺精湛」、你有强壮的身体。我们每个人都有一大把各式各样的牌。18 岁生日那天,钟声响起,「你今年18岁了,所有的牌都要你自己打了」,然后就是 Fly Bitch!自己扑腾去吧,没人为你负责啦!
 飞吧!碧池!
飞吧!碧池!
对!是的!剩下的牌都要我们自己去打啦!没有人要管你啦!法理上来讲,我们已经要为自己负责了,一个个高中生小碧池们都要自己飞啦!
飞行的目标是哪里?就是那个理想生活的模样。
怎么样形成理想生活的模样?这个过程实际上就是「内观」。
支撑内观背后的体系是什么?是公民教育。
怎么样发现自己理想的生活?观察、归纳和总结的能力。
怎么样去达成这个理想的生活?他就是一个非常非常长程的一个逻辑推演。
 打牌的过程就像做数学题一样
打牌的过程就像做数学题一样
我先有了一些牌,和一些机遇,它们能搓成什么? 接下来我获得了新的牌,再和周遭所遇到的事物一起,搓成新的手牌。这实际上就是一个不断不断推演、去创造条件创造新可能的过程,它的本质就是一道更为庞大的数学大题。
所以学科教育有它的意义。经常有人去抱怨说应试教育怎么样、学校教育怎样怎样。但实际上我们所经历的教育体系是非常完整和科学的,它在潜移默化的培养每一个「合格公民」独立生活能力的每个面向。
实际上整个教育系统已经很努力了,我之前也常抱怨,但是直到我读研了之后,我去了北师大,我看到协同创新教育创新中心那些老师,那些学生,哇,一个一个都黑眼圈,工作压力超大。他们真的已经很努力去让这个事情变的更好,现在的教育体系已经是能拿出来的最好的东西了。
我们的教育系统做一件事情做得非常好,就是在面对非常复杂的生活之前时候,帮我们做了一个「难度降级」,降级成学科教育。相对于庞大的生活议题,学科教育是更加纯粹的,整个教育经历最终的目标都是让个体能够一个非常复杂的环境下,通过「归纳整理」、「逻辑推演」去达成理想生活的模样。
那个理想生活是什么?就是最终的终极价值体系。
 学科教育:一个毕生发展的视角
学科教育:一个毕生发展的视角
这个系统始于我们出生,终于我们死亡。从我们出生那一刻起,我们和父母、和周遭环境之间的互动,我们的父母能不能满足我们最原始的需求和欲望,从这里开始,我们就在开始构建社会支持系统。通过不断的学习,不断的生活,最终发现并开始探索和追求终极价值。这个终极价值有没有达成,其外在表现就是一个人临终临终之后有没有悔恨,有没有遗憾。
 社会动力的构成
社会动力的构成
这一个一个的这种金字塔,就是一个个正在形成,和已经存在的终极价值。这些终极价值最后决定了一个社会前进的方向。这,个就是我们的当代社会。
道理谁都懂,但是道理不能说服这个任何人
我常讲道理谁都懂,但是道理不能说服这个任何人。
我当然可以给你讲角色采择理论是什么、价值观的构成是什么、依恋理论是什么、弗洛伊德怎么淦他娘,我也可以讲社会性的发展是什么、认知神经科学是什么、注意力是什么、那些科学怪人把被试推到磁共振里面狂扫人的脑子,然后得出了一些根本没有几个人能看得懂的结论。我也可以讲课堂三维目标,什么知识与技能,过程与方法,情感态度价值观。那些常出现在教参里面的话术,那些「通俗」的理念,什么跳一跳摘桃子,每一个老师的教案里面都有写呀,写了有什么用啊,你们班的小猴子不会跳,在树下都要饿死了呀。
道理谁都懂,但是道理不能说服这个任何人。因为道理是空洞的结果,探索这些道理的过程才是智慧。我们需要的不是道理,我们需要的是智慧。
智慧是最重要的,所以最后我想用这句话,为今天的风分享做一个结尾:不要停止思考。
通过这些思考,我们才能构建出一个更好的自己、才能构建一个更加美好的社会。
这个就是今天我想向大家分享的所有的内容,非常感谢你能看完这近三万字的文字作品,希望这个作品能对你有所帮助。我是螺丝,祝您平安喜乐,顺遂安康。
𝐼𝑛 𝑙𝑖𝑔ℎ𝑡 𝑜𝑓 𝑡ℎ𝑒 𝑠𝑢𝑓𝑓𝑒𝑟𝑖𝑛𝑔 𝑎𝑛𝑑 𝑡ℎ𝑒 𝑠𝑡𝑟𝑢𝑔𝑔𝑙𝑒𝑠 𝐼 ℎ𝑎𝑣𝑒 𝑒𝑥𝑝𝑒𝑟𝑖𝑒𝑛𝑐𝑒𝑑 𝑜𝑣𝑒𝑟 𝑡ℎ𝑒 𝑝𝑎𝑠𝑡 𝑡𝑤𝑜 𝑑𝑒𝑐𝑎𝑑𝑒𝑠.
]]>
 Windows 下一款名为 Zune 的播放器,其上下文菜单的实现
Windows 下一款名为 Zune 的播放器,其上下文菜单的实现 媒体库首页
媒体库首页 相册列表
相册列表 曲目列表
曲目列表 媒体库设置界面
媒体库设置界面 播放控制设置界面
播放控制设置界面 暗色模式的封面墙
暗色模式的封面墙 亮色模式的封面墙
亮色模式的封面墙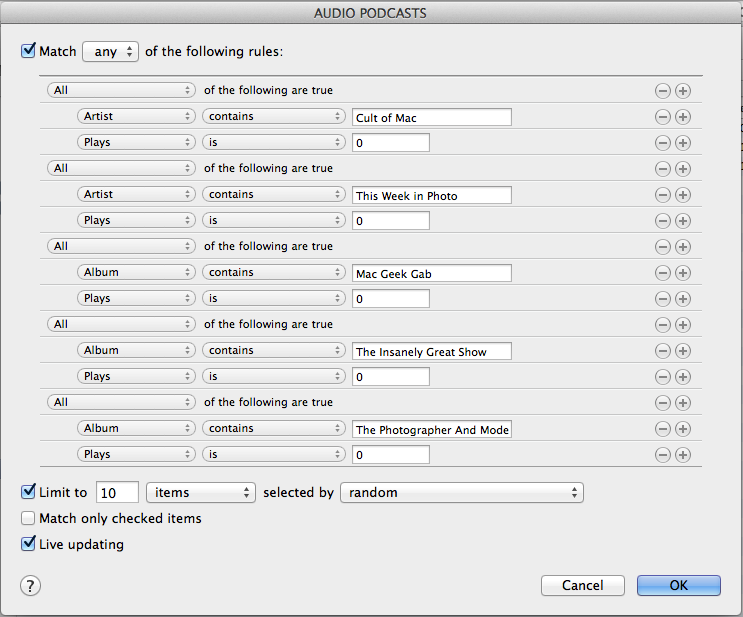 iTunes 的「智能播放列表」
iTunes 的「智能播放列表」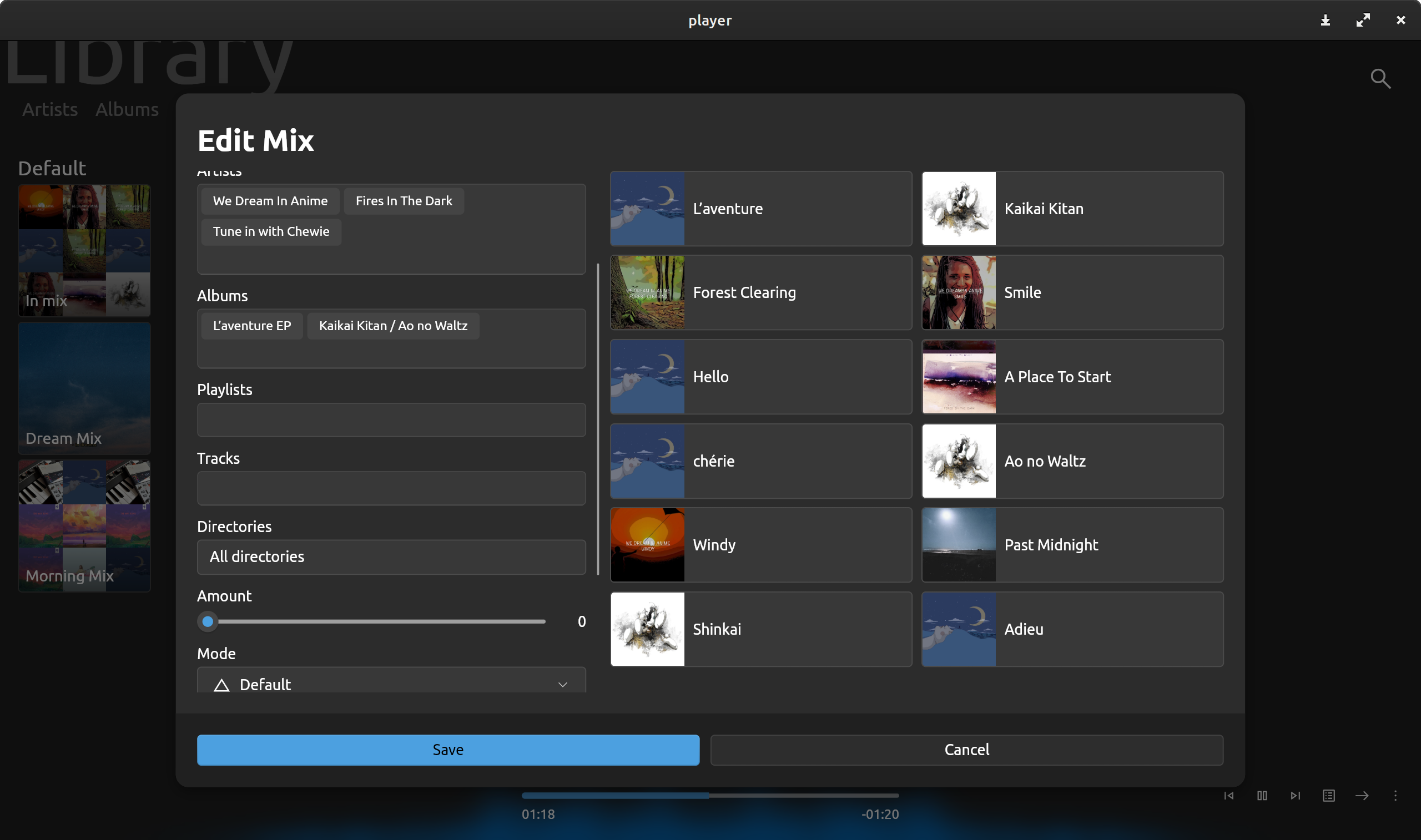 Rune 的 Mix
Rune 的 Mix 不,我不是画面当中的 CPU0
不,我不是画面当中的 CPU0