

这两天做了一个需要媒体播放的项目。基本上每次我做这种东西的时候都会去翻看一下浏览器的格式兼容列表有没有什么变化,但每次都会被 Safari 的弱智操作气到。在所有主流浏览器当中只有 Safari 是不支持 OGG 容器的。但很吊诡的是,它却支持 OPUS 编码,这种编码只能被塞到 CAF 容器里。
这个操作非常苹果。事实上 CAF 是苹果私有的封装容器,你几乎在其他平台上很难看到这种格式的踪影。而且苹果对它的支持很有限,哪怕是在 Safari 浏览器当中,它也仅实现了一部分的 CAF 标准,而非全部。要知道 CAF 容器的格式标准可是苹果自己制订的。
是的,这是一个充满阿婆公司风味的奇妙操作。iPod 年代要把音频往设备里面折腾的恐怖回忆又开始攻击我了,不过这一次我打算直面这件事情,从技术面解决这个问题。
背景知识
对于很多对媒体格式不是很了解的朋友可能就要懵了,封装格式、编码格式分别是什么?
实际上这是两个不同的概念,我们先从编码格式讲起。通常为了将一段我们能听得到的声音变成数字格式,我们需要进行「编码」这一个步骤。最简单的例子就是 PCM 编码啦,他把连续的声音拆开,每隔一段时间进行一次「采样」,取到振幅之后规规整整的把数字摆在一个文件里面。只要采样的频率够快(采样率),每次采样到的数据精度(比特数)够高,那么我们就能得到一个还原度很高的音频了。但是这样的编码方式有一个明显的问题:把数字一个一个堆叠在一起的存储效率非常低,我们小的时候常听的 CD,使用的就是 16 比特的 PCM 编码,一张光盘只能存一小时左右的音乐。
为了解决这个问题,确保文件的传输效率,我们可以考虑牺牲掉一部分音质,特别是常人难以察觉到的音频信息。根据这一原则,出现了诸如 MP3 和今天我们会探讨的主角:OPUS。它们都使用了不同的编码策略对音频文件进行压缩,感兴趣的读者可以读一下这份 RFC 来了解它具体的编码策略。
而容器则是用来承载这些信息的工具。我们举个例子,如果你是个单身汉,一个人吃饱全家不饿,可以选择在家炒完菜直接蹲灶台边上就这锅把饭吃完,还省得刷碗了。但是如果你家里有很多人一起吃饭,或者你要把饭盒带到公司准备第二天再吃,那就必须得装个碗或者装个盒了。
音频容器在做的就是这样的工作。举个例子,如果你希望在浏览器当中播放这些音频,那么它们最好是「流媒体」格式,确保文件可以一边传输一边播放。用户不需要等到把所有文件都下载完再进行播放。这就需要我们一段一段的将音频切开,打包成数个资源片段,并且做好妥当的标注。这样浏览器在收到这些数据的时候就可以按图索骥,知道「文件加载到这里就可以开始播放了」、「这些二进制序列包含了多长时间的音频」。
无论是 OGG 还是 CAF,都是这样的一种容器,OGG 格式的容器支持 Vorbis、OPUS 和 FLAC 编码,而 CAF 容器则同样提供了 OPUS 编码的支持。
Vorbis 编码是一种已经过时了的编码方式,在任何情况下如果有 OPUS 的话我们都应该尽可能使用 OPUS,而在浏览器的应用场景中其实我们很少播放无损音频,那么 FLAC 编码的支持也可以暂时放下。于是我们今天主要要解决的问题就是想办法让 Safari 认得出 OGG 容器当中的 OPUS 编码。
在开源界已经有很多解决方案了,比如说把 ffmpeg 编译成 WASM 放在 Web Worker 里面跑,但抛开这件事情的必要性不谈,WASM 的内存管理和加载管理、还有重新对文件进行编码的额外资源消耗都是一件很难处理的事情。着实属于为了解决一个问题创造十个问题了。
前端界梗小鬼共一石,万物 WASM 者独占八斗, 剩下两成 RIIR。
而针对这个问题,我提出了一个猜测,既然二者支持的都是同一种 OPUS 编码,那么我们能否通过简单的二进制拼接来实现对 OGG 容器的兼容。
容器格式的探索
那么我们要做的事情就很简单了。分别实现一个 OGG 和 CAF 格式的 Parser 来比较一下这两种格式内部存储的数据究竟是否是一致的。
首先,我们使用 ffmpeg 来制备本次研究所要使用的音频样本:
ffmpeg -i ./source.mp3 -c:a libopus "target.ogg"
ffmpeg -i ./target.ogg -c:a copy "target.caf"这里的 -c:a copy 是很重要的,它确保了 ffmpeg 不会对音频文件进行重新编码,这样我们可以在控制编码方式这一变量的前提下来剖析两种容器的差异。
接下来就是编写一个简单的解析器了,为了图方便我选择了使用 Deno 来完成这个操作,写的时候也没什么章法可言,可以说是想怎么写就怎么写,非常随心所欲了。
我们做的第一件事情是照着 CAF 格式规范 来解剖一个 CAF 容器格式的文件。从文档当中我们可以看出,一份标准的 CAF
格式文件包含一个文件头,以及数个 chunk,其中每个 chunk 由一个 UInt32 开头,标记这个 Chunk 的类型,接下来包含了一个 SInt64 标记这个 chunk 有多长。因此在解析完毕文件头之后,就可以开始沿着这两条数据逐一对文件进行切割。实验性的代码实现在这里各位读者可以酌情参考自己的 SAN 值进行阅读。
在拆开一个 CAF 之后我们会发现,它大致包含了几种必要的 chunk 类型:
desc描述了文件的采样率、编码格式等信息;chan描述了多声道文件的声道配置,比如说哪颗音响放在哪边;data被编码的音频文件二进制序列;pakt一份 packet 表,它记录了data被切分成了几个可以独立播放的小单元,每个单元究竟有多长。
接下来,就是照着 OGG 容器格式规范实现一个 OGG 格式的分析器啦,如果你把文件打开,会发现 OGG 容器的实现更加灵活一些。一个
OGG 容器当中可以包含很多个「流」,这个流可以是不同类型的信息,可以是音频,也可以是字幕。每个流都有自己的 ID。每个流内的信息又会被分成数个小的 pages,按照序列号首位相连。播放器可以按照流的编号和 pages 的编号把不同类型的信息粘在一起,进行妥当的解析。每一个 page
都被 Oggs 四个字符隔开,并且包含了一些必要的元信息。
在这些元信息当中 segmentTable 是尤为重要的,它记录了这个 page 当中究竟包含了几个segment(在 CAF 容器当中等价于 packet),把这些数值加在一起我们就知道这个 page
有多大了。只需要把索引往后跳这个数值,我们就一定会遇到下一个 OggS 标识。
而对于 OPUS 流,第一个 page 一定描述了文件采样率等编码信息,而第二个 page 则描述了一些元信息。比如说我们手里的文件,它的元信息是:
{
vendorString: "Lavf60.3.100",
userCommentString: [ "encoder=Lavc60.3.100 libopus" ]
}这些信息告诉我们这个文件是怎么编码的,以及用什么编码器编码的。这里我们用的是 libopus,也就是 ffmpeg 内置的选项啦。
我的实验性 OGG 解析器实现在这里你感兴趣的话可以简单看一看。请注意这里的代码写得都很潦草,后面浏览器内的版本有好好整理过。如果你只是想简单的把 OGG 文件拆开的话可以看这里的实现,想正儿八经用的话还是推荐看后面大仓库里面的版本。
接下来要做的事情就很简单了,我们来粗糙的比对一下 CAF 容器的 pakt 和 OGG 容器的
segmentTable 究竟有没有对应关系。
这是 CAF 容器的调试输出:
{
header: {
numberPackets: 5822,
numberValidFrames: 5589120,
...s
},
body: [
300, 208, 127, 124, 291, 251, 203, 236, 213, 120, 285, 169,
...
]
}这是 OGG 容器的调试输出:
{
...
pageSegments: 55,
segmentTable: Uint8Array(55) [
255, 45, 208, 127, 124, 255, 36, 251, 203,
236, 213, 120, 255, 30, 169, 169, 169, 197,
...
]
}我们能看到,这里的数值基本上是对的上的,但是又有些不一样,比如像是 CAF 容器当中的第一个
packet 尺寸是 300,OGG 容器当中的前两个值加在一起才是 300。造成这个差异的原因是
OGG segmentTable 的编码方式造成的。让我们来读一下 RFC 3533 的第七页:
- Note that a lacing value of 255 implies that a second lacing value follows in the packet, and a value of less than 255 marks the end of the packet after that many additional bytes.
- A packet of 255 bytes (or a multiple of 255 bytes) is terminated by a lacing value of 0. Note also that a ‘nil’ (zero length) packet is not an error; it consists of nothing more than a lacing value of zero in the header.
翻译成中文就是:
- lacing 值(也就是
segmentTable当中的某个数值)为 255 意味着紧随其后的数据包中还有一个 lacing 值,而小于 255 的值标志着数据包的结束; - 255 字节的数据包(或者 255 字节的倍数)通过一个值为 0 的 lacing 值来终止。
所以我们只需要调整一下 segmentTable 的解析方式,就可以得到正确的结果了。实际上另外一个 OGG 容器解析器的实现也犯了同样的错误导致后来分析 OPUS 数据包元信息的时候出现了错误的结果。这个问题可以说是非常阴险了。
另外一方面, CAF 格式的 pakt 区间也是用另外一种方式进行编码的,只是这里我们恰巧没有撞到而已,让我们读一下苹果的文档:
The numbers describing the size of packets or frames per packet are encoded as variable-length integers. In this encoding scheme, each byte contains 7 bits of the binary integer and a 1-bit continuation flag—the high-order bit in each byte is used to indicate whether the number is continued in the next byte.
翻译成中文就是:
描述每个数据包中数据大小的数字被编码为可变长度整的数。在这种编码方案中,每个字节包含了七个 7 bit 用于描述数值本身,以及一个 1 个 bit 的「连续标志」用于指示数字的编码是否在下一个字节中继续。
看起来有点抽象,不过实现起来并不难,你可以在 GitHub 上直接找到这部分实现的源码。
寻找对应关系
下面要做的事情相对简单,我们只需要找到两个文件数据存储的对应关系即可。这边截个图,那边截个图,两个图放在一起,做做连连看,就可以找到二者的对应关系。下面的这张丑图很直观的列出了两种格式的比较。
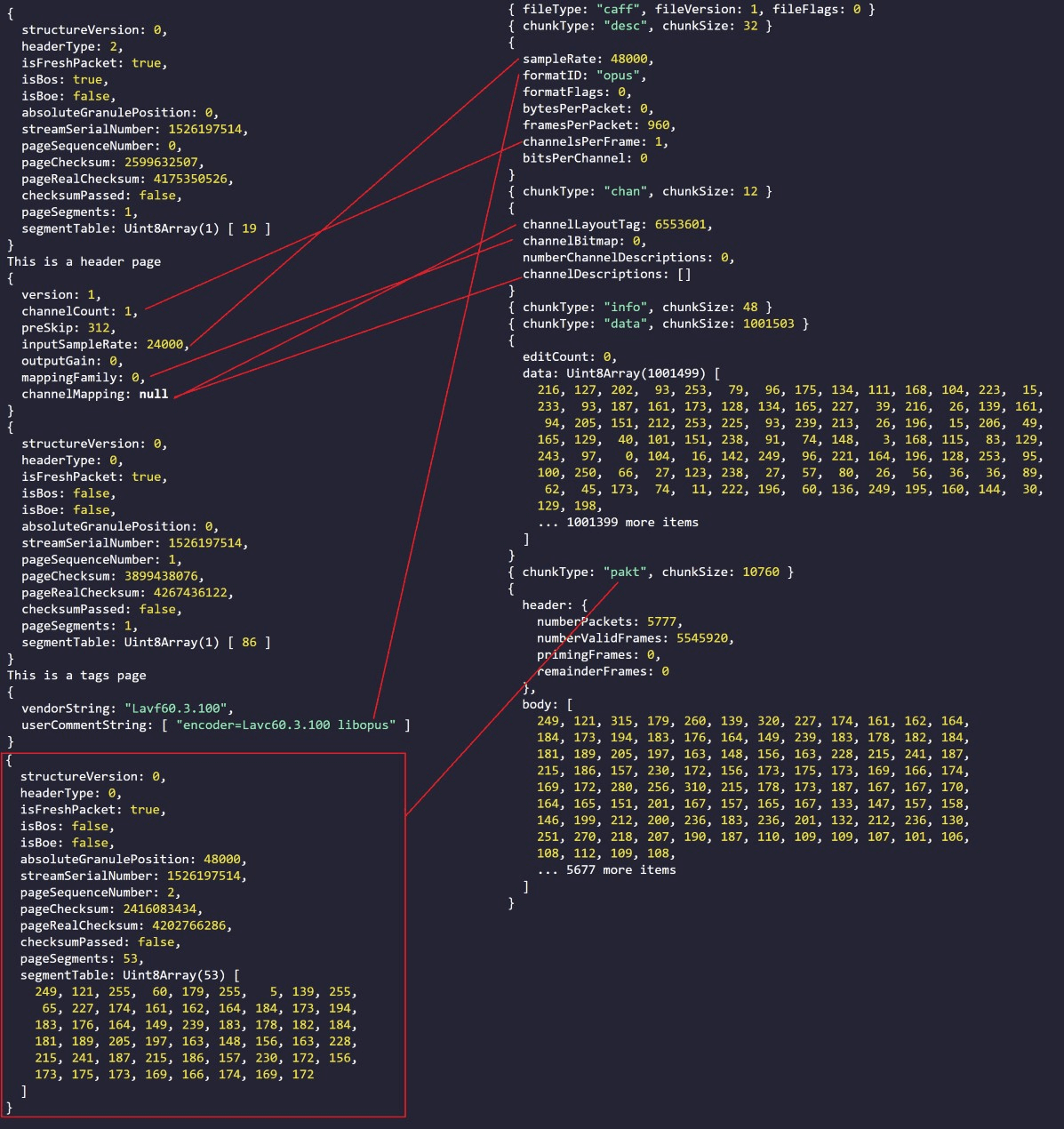
从这张图当中我们可以看出,「采样率」、「声道数量」、「OPUS 二进制数据」这几个条目的信息可以原封不动的拿过去用;
「声道排布」这个数据需要打表重新对应过一遍之后才能,根据 RFC 7845 OGG 容器本身支持 5 种声道排布,并且所有声道的布局都是固定的,而坐拥 2B 厂的 HIFI 玩家苹果则支持了更加复杂的声道排布方案。不过很不巧的是,三声道音频在两个方案中并没有重叠的布局方式,所以我们只能选择一个最接近的方案进行转换,如果你富甲一方,家里有一大堆音响,并且在用 Safari 播三声道的 OGG 音频,那么左中右的确是会窜的,不过考虑到这个情况真的很罕见,所以我们可以等有人报 bug 了再来修它。
最后就是最麻烦两个参数了,CAF 容器当中的 framesPerPacket 参数,还有给 Packet 做打表的流程。对于固定码率音频(CBR,每个音频片段的码率一致)还有可变码率音频(VBR,每个音频片段的码率不一致)的情况,这两个信息的转换方式是不一样的。
因为非常先进 OGG 容器默认假设自己包装的音频都是 VBR 的,所以开发者得等所有数据都下载完毕之后,对所有的 segment 逐个进行分析,RFC 6716
对此进行了相当详细的介绍,感兴趣的读者可以看一下。如果你不嫌烦的话还可以顺便看一下这块解析的具体实现总而言之,每个 OPUS segment 都包含了至少一个 byte 用来描述这一段音频有多长时间,编码方式是什么。如果你发现所有 segment 的配置都是一样的,那么恭喜你绕过了第一个坑。
接下来就是简单的数学计算题了,CAF 格式当中的 frame 概念对应到 OGG 容器上实际上是samples,也就是 time * sampleRate / 1000。这个 time 可以从 OPUS 的 第一个
byte 当中查到。通过这个数学计算,我们就可以把 framesPerPacket 这个数值填进去了。
pakt 包里面的表则可以简单的把所有 OGG segment 当中的 table 拍扁成一个大数组,原封不动的喂过去。
但如果你发现自己的音频文件是 VBR,则需要给 framesPerPacket 填 0,然后重写一遍 pakt
表,表的容量要翻倍,每个 packet 的描述都要由两个数字完成,一个是包的大小,另外一个数值是包的帧数,计算方式和前面的介绍是一致的。
但是这个表打完之后,我们会惊喜的发现,在这份 2005 年就已经发布的规范中介绍的 VBR 编码方式直到 2023 年的 iOS 17 才得到了正常的支持。换言之在 iOS 17 以前的浏览器中,这样的音频文件是没办法被正常播放的,这很苹果。
苹果文档原话:
Variable bit rate, variable number of frames per packet (such as Ogg Vorbis): mBytesPerPacket is zero, mFramesPerPacket is zero.
你都在你自己的文档里面提了 Vorbis,但是你自家的浏览器却不支持 Vorbis,相对的整篇文档都对 OPUS 只字未提,所有东西都要靠我猜,这很苹果。
工程实现
最后就是工程实现啦,没什么难的,文件怎么读的就怎么拼回去,写完了找几个样例文件,读一遍,重新构造一遍,看看两份结果一样不一样,一样就没问题了。
虽然看我洋洋洒洒写这么一大堆,但是从头到尾大宗的工作都是把二进制文件撕开再重新粘回去,在浏览器里面做这个操作的过程对于用户来讲几乎是无感的,性能非常好。
本来我是想着所有操作都用 Generator 来做流式处理的,但是拜 CAF 的天才设计所赐,在读到第三个 OGG Page 之前我基本什么都生成不出来。如果你要判断 VBR 或者 CBR 的话,那必须得等到整个文件读完才行。所以我索性直接假设所有文件都是 CBR 了,反正 iOS 17 以下的 CAF 根本不支持 VBR,针对 VBR 的播放后面我有别的招,iOS 17 以下照样能做。只是代码还没写完,写完之后我再开一篇文章介绍具体的做法。
对于终端用户,你只需要调用包提供的 fetchOggOpusFile 再把它和 oggOpusToCaf 串在一起就行了,仓库里面都有使用的例子在这里就不多赘述了。API 设计的非常底层,如果你想做成真正的 Polyfill,可以直接把它套在
Service Worker 里,在文件输出给 DOM 之前做拦截和转换,如果你只是想在 JS 层面用的话,直接把二进制数据流拼成大的 Buffer,喂给 Audio Context 或者转换成 Object URL 塞进 Audio Element就好了。
这很苹果
最后我想再来聊聊 CAF 这个格式的设计。在我看来它的设计是相当失败的。苹果标榜自己的文件格式可以一次写入,也可以作为流媒体格式进行分享。但这两件事情在 CAF 的语境下是不兼容的。
如果我们想 One Pass 写入文件,那么 pakt chunk 必须被放到整个文件的最后面,但是如果它被放在最后面了,那么在进行流媒体读取的时候,在整个 data chunk 加载完之前都没办法知道整个文件的表是怎么打的,自然也就没办法播放音频了。
那如果你想让媒体本身支持流媒体读取呢?要么就在编码的时候做回写,要么就在文件编码完毕之后做一个转换,这两种方式都算不上是 One Pass 了。
但是像是 OGG,甚至上古格式 MP3 都没有这种问题,这格式的设计可以说是很失败了。
现在让我们再来看看,都 2023 年了,是哪个小可爱还没支持开源、开放、甚至是 IETF RFC 的 OGG 格式标准呢?啊哈!原来是苹果!它甚至还在用自己的废物私有格式。
这很苹果。

Loading comments...