

趁着五一假期,我又开始折腾一些奇奇怪怪的东西了。这次做的是一个由 Joy-Con 和 PC 驱动的体感视觉小说系统。
实际上这个项目始于两年前,我玩过很多 Switch 上的「体感游戏」,它们都很好玩。但是没有一款达到了我对理想「可控有氧运动」的需求,于是便想着要么自己做一个。实际上在我的人生中有过一次非常成功的「减重经验」。
在一个初中的寒假的时间,一个完全做不了任何运动的小胖子,成功的把凸出来的肚子抹平变成了一个名副其实的「瘦猴」。做法也非常简单,一边看电视一边原地跑,每天跑一个小时,就这么跑了一个月,开学穿衣服的时候我发现自己身上的「肥肉」竟然被消灭光了。
一切只始于我和同学在家里打赌,原地跑一次跑一个小时看看谁先累趴下。事实上这个过程完全不累,只是单纯的大量流汗。这大概是我人生当中第一次通过运动激发了内啡肽的分泌,获得了「快乐」的感觉。因为没什么「气喘吁吁」的难受感觉,后面就坚持下来了。
体感游戏
但自从开始工作之后,运动习惯就很难保持住。在公司里面天天跟傻逼老板打乒乓,晚上光能走回家就已经精一杯了,如果再压强度比较高的运动,第二天就会起不来床,非常痛苦。
为了能对运动「有所记录」,并且通过一些「游戏化」的方式获得奖励,形成正循环,我曾经花了一些时间,刷通了能买到的大多数「Switch 体感游戏」。
而作为一个极度龟毛的人,在体验了大量「体感游戏」作品之后,总有一种隔靴搔痒,没有戳到点上的感觉。
Fitness Boxing
这是我玩的第一款健身游戏。游戏本身的设计没有太大问题,上半身毁灭者,每天打拳半个小时,刷刷积分和成就。
但这套游戏最大的问题是动作检测做得不好,尤其是下蹲动作非常难检测出来。因此,对于大多数玩家来讲,必须得进设置界面打开很多「自动判定」,有点尴尬。
以及成就系统上,它有很多引导你尽量「多做运动」的成就,像是准确判定的次数、运动总时长、打出拳的总数,甚至有一些刁钻的,「使用所有背景音乐完成游戏」。但也有一些设定比较尴尬。
比如要选择所有角色,给每个角色都换装,并且打足够多的局数。虽然个人能够理解它还是想要让你多运动,但是被逼着跟不太喜欢的角色打拳,来达成「全成就解锁」还是有点不大舒服。
这款游戏整体设计都很好,画面很不错,音乐选得也算有品位。至今为止,大多数成就都有解锁, Switch 上的总使用时长为 165 小时。
健身环
说实话,要我评价的话蛮糟糕的。这是所有健身运动产品当中唯一一个有阻力训练的(就那个环),这是值得称道的一个点。
但剩下的就没啥好夸的了。尽管把有氧和力量训练结合在一起是一种不错的尝试,但关卡之间你需要配饮品、升级技能、选择技能组合,在锻炼的时候你得自己选要做的动作。这种「积极主动」把运动过程切的非常碎,导致心率保持会变得有点问题。
在健身环上,所有运动行为完全是由玩家控制的,跑步的时候你可以慢慢跑,偷偷懒,运动的时候也可以全程选「瑜伽」,两次动作之间也可以「偷偷休息」,这都严重的影响了了锻炼效果。
最后,我对「任天堂式」的「游戏化」设计非常不满。尽管小游戏设计得上非常巧妙,但这款作为运动游戏的设计并不理想,因为游戏元素和通关与玩家的游戏技巧有关,这是极为不合理的。
一周目打完,二周目达到了一半,总使用时长 95 小时。
健身巡游
相当不错的一款产品。强度很够,Fitness Boxing 主要是动上半身,而这款主要是包含了大量的下半身运动。你知道的,练腿总是最痛苦的,所以才会有大量「练胸不练腿」人士。
和有氧拳击不同,这款游戏对于训练者的心率的掌控能力更强。Fitness Boxing 除非你真的非常刻意用力打拳,否则心率是有一个很低的瓶颈的。很不巧的是你打多了,动作自动化了之后很容易动作幅度就会变得小。但是健身巡游主要都是动下半身,几乎没啥「动作幅度变小」的空间,所以每次运动的体验都很理想。
但也有些可以说的点,比如动作设计有点「过难」,比如要求动上半身和下半身的同时左右动,经常搞到我「顺拐」,一节打完之后满脑子问号。
再比如它对每种动作的难度标记有点不准确,有几个动作明显会让你累到想死,但是会被抽风般地编进同一天的运动方案,做完之后累到想抱住马桶吐(是真的有反胃的感觉,不是某种形容)。有几天又莫名其妙的很简单,做到最后也没啥感觉。
最后,它的力量训练因为不带阻力所以难度明显更低,有点充数的感觉。
不过因为气氛上心率维持的还不错,所以我给很高的评价。
目前的进度是角色所有的衣服都收集完毕,因为是最近才买的,所以总使用时长只有 40 小时。
Let’s Get Fit
这款游戏的设计显然是针对专业运动玩家,难度曲线非常陡峭,让人不是「没感觉」就是「累死」。
视觉设计「唐」到不行,选曲也是非常尴尬。唯一值得称道的是他能对你的运动轨迹做出反馈,而不是以「一次动作」为单位做反馈,这样你可以对动作哪里出了问题有更好的理解。但因为教学不足,玩到最后你有可能都没办法知道自己究竟哪里做得不好导致没拿到高评价。
这种明显面向「专业玩家」的设计思路有一个很大的问题:已经很擅长运动的人为什么还需要一个「体感游戏」来帮助自己保持习惯或者做得更好?直到今日我都没想明白这个问题的答案。
加之程序的稳定性有很大问题,经常强退,加载速度还慢,导致我玩了一段时间之后就弃置了。
总使用时长 10 小时。
家庭训练机
尽管哔哩哔哩上某个专门做测评的人给了它很低的评价,但是我对它的印象非常好。抛开那些完全无效的「上半身运动」,里面以跑跳为主的运动,效果都非常好。「十分钟慢跑」、「跳绳」是我最喜欢的两个项目。运动全程都能把心率维持在较高水平。
然而也有一些遗憾之处,比如每次超慢跑只能持续 10 分钟,而一次理想的运动应当持续至少 40 分钟。再比如跳绳的动作检测的确是有些不准,加之每次失败,摇绳速度就会回归最初的水平,让挑战难度低了不少。
这个月刚买的,虽然非常喜欢但玩的时间不长,拿到了铜牌,4 小时。
我理想当中的训练程序
在我的脑海中,一个好的训练程序主要有几个维度需要考虑:
- 视觉听觉体验:至少是一个现代的内容风格,不说有多养眼但至少看起来不要辣眼睛,可以没有选曲,但如果要选曲的话至少得不让人感到尴尬;
- 运动强度:游戏在运动过程中是否能够持续维持心率在一个较高水平,这对于燃烧能量和提升体质有重要作用;
- 不尴尬的游戏化:至少「游戏」的难度应当与运动强度有关而不是其他「游戏操作」的难度;
- 「控制方向」:对于一个运动产品来讲,应当是游戏「控制你」做什么动作,用什么节奏做,做几次做多久,以达成预期的运动效果。如果做到了就给激励,没做就给反馈,在积分上有所反应。
上面我体验过的产品在这些维度上多多少少都有点让我不满意的地方,但考虑到咱又不是不会写代码,那为什么不自己做一个呢?于是乎我就开始琢磨着搞点事情。
得益于初中时成功的减肥经验,我决定将目前的开发精力收束在「超慢跑」上。事实上只要做好这一点就能够创造很多价值了。
超慢跑
在运动技术上来讲,这种锻炼的方式被称作「超慢跑」。但是这个词是这两年才火起来的,当年能撞出这种方法完全是碰大运。
字面意思,超慢跑就是用超级慢的速度来跑步,可以是在室内原地跑,也可以是在室外(像个街边二傻子一样)用走路的速度跑。旨在以较低的强度和速度进行。这种运动特别适合那些身体上还没有为运动做好准备,但想要着手改变身体状态的人们。
超慢跑的优势在于其较高的能量消耗效率和较低的消极体验。对于那些没有办法坚持跑步的人来讲,最大的诱因或许就是气喘吁吁、上气不接下气的感觉,以及每天需要专门划出时间出门。
这跟做用户体验设计是一样的,阻力多一点用户走到最后一步的成功率就会少很多。超慢跑作为一种运动在极大程度上消解了这些「负向动力」。你可以可以在室内原地运动,一边跑一边追剧或看球赛,都可以。
超慢跑的关键在于稳定节拍,效果最好的节奏是每秒三步,即每分钟180步,以达到最佳效果和最舒适的跑步体验。而如果你每天通勤上班的话,也可以用接近于走路的速度在街上跑。同样的时间,能够收获 2 倍多的能量消耗,还不是很累,可以说是赚到上天。
目前能找到系统性介绍「超慢跑」书籍就只有一本田中宏暁的《スロージョギングで人生が変わる》,我自己看不懂日文,所以用 GPT 跑了一遍整本书的翻译,虽然做不到「信达雅」但读个大概是没问题的。
我对这本书的评价并不是很高,对于科学原理方面的论述充斥着一股子民科的味道,但关于运动实作的方面问题倒不是很大,至少不会导致运动伤害,如果你对这个话题感兴趣的话还是可以读一读,毕竟也没什么别的书可以看。
两年前的失败与如今的续坑
当时,我因为想记录超慢跑而开始了这个项目。然而,由于各种技术问题,项目进展并不顺利。
最一开始的场景搭建还算顺利,但到传感器数据处理,就开始吃瘪了。对于一名曾经搞脑科学的「玩家」,看到这种数据自然想到的就是「滤波器」、「傅里叶变换」之类的骚操作。但 JavaScript 生态下的信号处理就是一坨屎,比 Julia 的信号处理生态还烂。换了各种库都没办法把开始处理数据,搞了几天都搞不定于是就弃坑去玩其他东西了。
但你懂的,作为一个龟毛人,心里对已有产品有不满的时候,就一定会产生造轮子的想法。恰逢两年之后,总算有机会用 GPT4,于是事情开始出现了转机。
对话是以「启发式」的方式展开的,先请 GPT 介绍「健身环」这款游戏。它很详细地给我讲解了游戏内容。我进一步询问跑步在健身环中是如何实现的,特别是步数监测。GPT 告诉我,可以通过设定一个简单的阈值来实现,当加速度超过这个阈值时,就模拟出腿抬起来的动作;当加速度降下来时,就模拟出腿落下去的动作。
我听后觉得这个方法很不错,于是继续追问是否有更好的解决办法。GPT 建议我设计一个状态机,通过高点和低点来确定步数,这样可以使整体更加稳定,避免出现虚假步数。
在对话当中 GPT 提出我可以使用滤波器来滤掉高频噪声,并且给出了一个我从来没见过的滤波方法。通过平滑新旧数据之间的关系,降低旧数据的权重,提升新数据的权重,从而滤除高频噪声。
「宝贝,野啊!」搁学术界想要高低我也得整个带通滤波器,有病的时候还得上个小波,这也行?这不 Lerp 吗?还能拿来做滤波?哦,不对,Lerp 在本质上也是个滤波。但当年做信号平滑高低也得维持个数组开个窗,这好家伙,我直呼好家伙,用这招连开数组都不需要了。
工业界的玩法与科研领域的玩法确实存在很大差异,牛逼,确实牛逼。
话都讲到这了,能不让它直接帮我写个 TypeScript 的实现嘛,非常出乎意料的是它生成的 Code 高度可用。于是我又多加了点要求,请他生成一段跟现有 Web HID API 集成的 Code,东西就跑起来了!
他妈的!这玩意跑起来了!我当年可是折腾了好几天,屁都没整出来。如今这玩意让 GPT 给整出来了,要知道我当年差点就去看动捕的论文了。
但后来也闹了个乌龙,因为我的 GEM12 没有蓝牙天线,蓝牙信号非常差,不光丢包严重,数据处理也几乎不是匀速的,导致经常丢步数。搁一般产品里面可能平滑一下算个步数,让角色沿着固定速度往前走就行了。但我偏不,敝人非常追求那种实境的感觉,角色的行为必须精确到步,你踏一步场景就往前走一点。
为了处理这件事情我把数据拉出来放 R 里面用 ggplot 画图之后一顿观察,疯狂调参。每次调完都得上机实际体验一下到底效果好不好,结果当天晚上人直接给累趴下了。
后来本着「工欲善其事必先利其器」的想法,写了个简单的调试器,才发现了信号不匀的事情,第二天买了个带天线的蓝牙适配器才算把事情解决了。
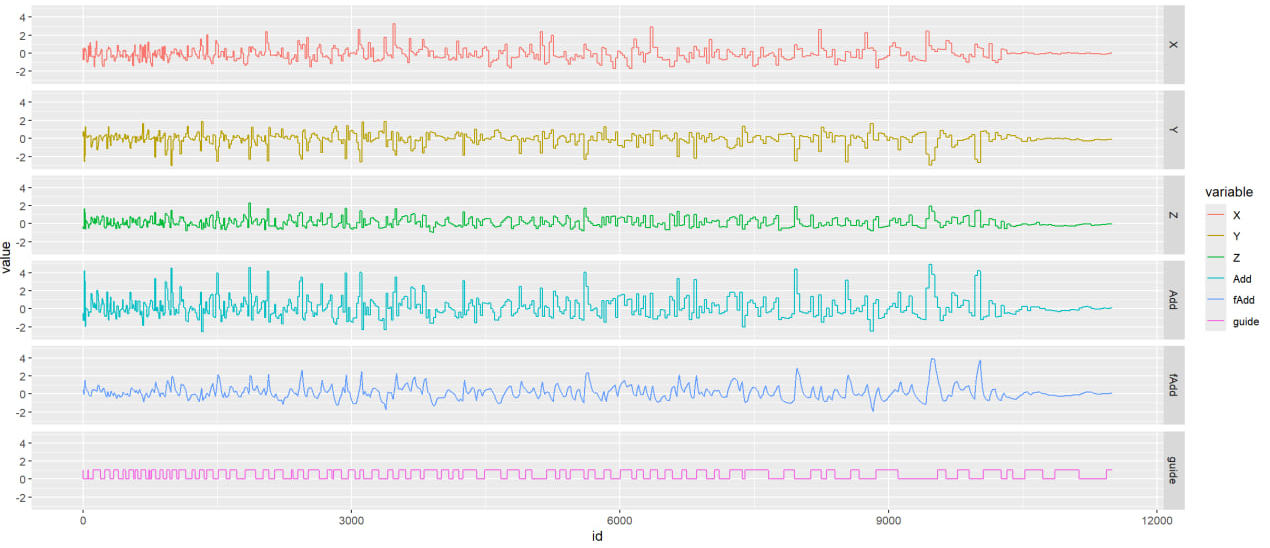
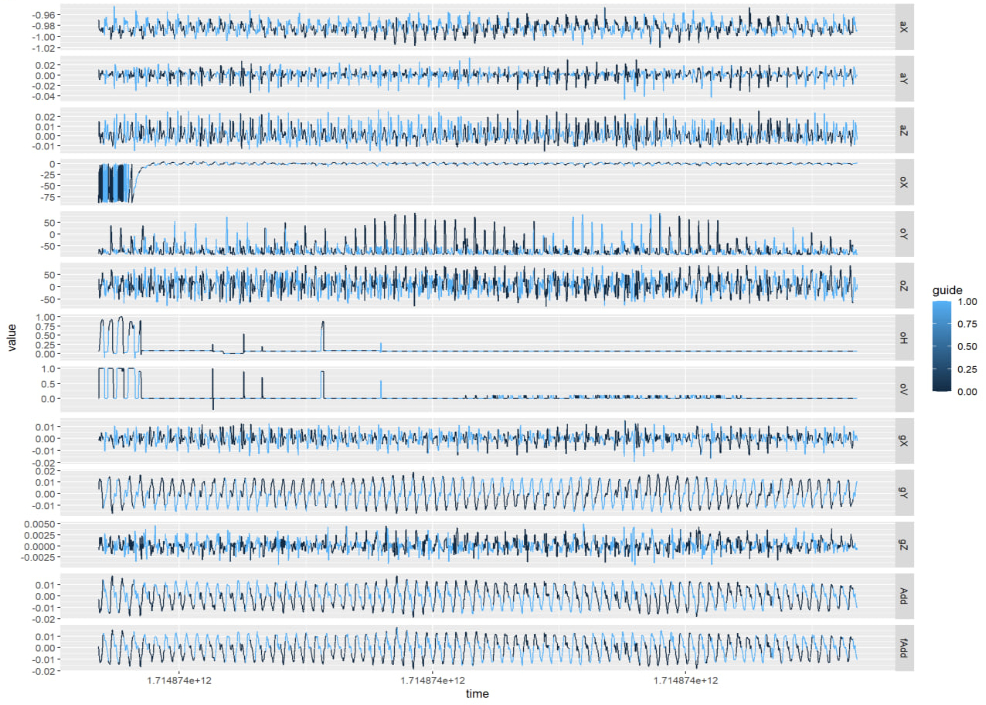
看到干净漂亮甚至不需要滤波的信号,我的眼角流出了不甘的泪水。
淦,我竟然因为这么荒谬的理由浪费了整整一个晚上……
计算机图形学和技术美术!
除了这些荒谬事情之外,就是正常的 Technical Art 领域了。
Day 0
这部分是假期前准备的工作:地面设计。
凭借着当年在基本操作修「老王下山」那个交互的经验,很快的就做出来了一个无限宽广的随机地面,角色奔跑的时候区块能自动加载和卸载。
这是一个常见的设计,但它有两个问题:如果平面是平的,那么为了填满整个视野,需要的资源会随着距离的增加而增加。尽管可以做区块加载卸载,但它会带来视觉上的问题,比如物体的闪烁。玩过 MC 的玩家肯定知道,渲染距离开太近就会很明显的感受出来区块加载时画面的跳变。
当然可以上 LOD(细节层次距离)处理,降低远处物体的细节,以提高渲染效率。但……有必要这么对自己吗……我可只有一个短短的假期……还是想做点跟内容有关的事情……
当然有更优雅的解决方案——《动物森友会》。动森采用了一个圆柱形的世界设计,当玩家沿着纵深移动时,实际上是圆柱在滚动,这样一来,视野内需要加载的内容就会变少很多。
我尝试了这种方法,但发现地平线变得非常明显,效果很奇怪,不再像是一个真实的空间,画面纵深变得很窄。不过将圆柱拉长三倍,变成椭圆之后,画面就变正常多了。
画面上的方块是占位符,主要用来放花花草草。这个时候画面当中的元素已经能够跟随训练者的踏步前进了。
Day 1
我脑海当中,画面场景应当是一个一望无际的大草原,布置上树木和鲜花,训练者能在这片无限延伸的草地上自由奔跑。
如果东西很多,就不能用 THREE 画一大堆单独的草再往 GPU 发,因为 Draw Call 多了会很卡。不卡的办法也有,instancing,但是得写 Shader。
在游戏开发中,写 Shader 一直是我觉得比较困难的事情。记得当年在进行基本操作时,面对那些复杂的 Shader,由于看不懂其中的数学原理,我总是不敢轻易去碰,毕竟我是怂人。
但这一次,咱不是有 GPT 嘛,加上网上也有现成的教程教怎么用 Shader 画个大草原,于是我就跳进去了。
虽然过程混乱,教程和 Demo 项目也没做得很细。但流程好在清晰,于是我就根据它提供的思路和参考代码,自己徒手写了一遍。
第一天主要熟悉 API,以及唤醒那些曾经看过但是从来没用过的计算机图形学知识。
第一步先把 THREE 官方的 Buffer Geometry 范例复制下来,然后慢慢改。先把漫天飞舞的三角形变成正方形,再把正方形变成长方形。最后,根据每个顶点的 y 轴坐标决定旋转角度,越高的点旋转角度越大,这样草就弯下来了。
之前很多匆匆看过一遍的知识到当下基本已经忘光了,比如 Vertex 定义之后要用 index 连成平面这种事。在这段时间我基本就是疯狂戳 GPT 问各种问题,估计要是个物理暴躁老哥,早被我戳爆了。但 GPT没脾气,一问一答节奏非常好。我只要描述症状,提供代码和 Log,它就能告诉我下一步该如何操作,即便这些都是很基础的问题。

Day 2
第二天主要做的事情是让草动起来。这个时候很明显能感受出来,当需要调试风向或更复杂的东西时, ChatGPT 的帮助就有限了。这时,工程师的技术嗅觉和经验明显会更有用一些。
调整一下弯曲参数,用噪声生成一个向量场,让草沿着一个规律弯折而不是像马桶刷子一样乱弯,然后把时间戳当成 uniform 传给 shader,做一个和时间有关的噪声,给弯折程度和玩着方向上个和随机向量有关的权重,事情就算完事了。
事情看起来简单,但是矩阵操作顺序是有说道的,因为操作顺序不对,导致草弯到了地平线下面,整个草场变成了一根鸡毛掸子,甚至群友还夸我您这鸡毛掸子做得真像!
最后调整一下草的形状,变成尖尖角,第二天要做的第一件事情就完成了。
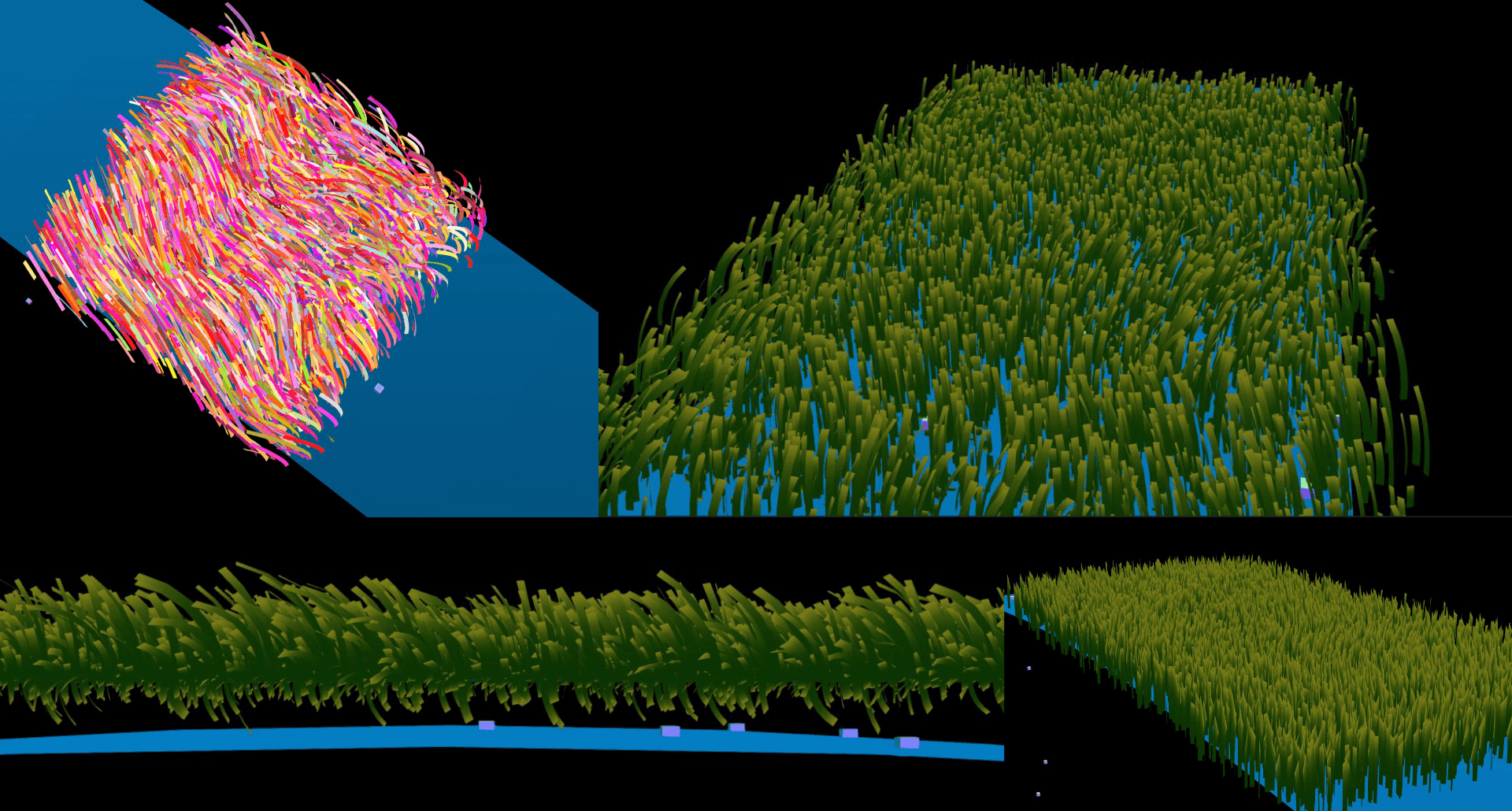
Day 3
考虑到往画面上放大量三维模型会不可避免的搞出各种性能灾难,为了让日子过得简单点我决定直接塞平面贴图,并且把它当成一种「能够减少开发量的视觉风格」。主要参考的对象是《饥荒》。但很明显这画面让我实现成了某种完全不一样的东西。
用 Stable Diffusion API 生成一些二次元动漫风格的树木,然后喂给一个非常神奇的抠图网站去背。我说这网站神奇是因为它完全用 WebGPU 驱动,抠图模型是在本地跑的,也不要钱,真是佛心。
这些最简单的步骤做完之后,真正麻烦的事情开始了,第一个问题就是高清贴图。因为用户的显存有限,通常我们不能用分辨率太高的贴图,不然贴图本身加上 mipmap 会直接把显存怼爆。
为了处理这个问题,需要用 Basis 格式的贴图,但这玩意的压缩工具非常玄学(主要还是我没经验)。需要开的参数非常多,比如生成贴图的时候得用 -flipY 把贴图转一下,不然就会变成「倒立生长之森」这种恐怖的玩意。再比如,它会自动重新映射色彩空间,把 sRGB 映射成 Linear,但是
THREE 那边又会按照 sRGB 来读取贴图,导致画面渲染变得非常诡异。
反正最后我来来回回调了好长时间参数才把贴图捋顺了。
再比如,栅格化领域知名难题,半透明。如果你玩过 THREE.js 这类东西肯定会对半透明有印象。叠上 instancing 之后会让问题变得更加复杂。也是因为这个问题,THREE 官方一直都没给 instancing 加透明度支持。
It’s not possible, mainly because if that was allowed the first thing people bump into is that the order in which transparent objects get renderer is incorrect.
mrdoob, 2020
你不加 opacity 支持就没问题么,半透明贴图不照样吃瘪,笑死(bushi——)
最后一顿折腾,一开始是关 depthWrite,但是 Z 轴方向的深度会出问题,后来 GPT 给了我个招:在渲染时丢弃透明像素。
if (textureColor.a < 0.99) discard;赞美 GPT。
最后,就是限制一下渲染区域,用取模运算让树只在可视范围内渲染,避免浪费计算资源。再多加一些贴图的种类,这一天就算折腾完了。

(对了,前面说的折腾信号差点累死也是在这天发生的)
Day 4 ~ Day 5
最后两天主要做的事情是加 GUI。用 CSS / HTML 写 GUI,做路由管理之类的事情明显比调 WebGL 要冗杂、没有成就感。
首先定了一下基本的设计规范:视觉上,毛玻璃、渐变亮色细边、Raleway 字体、加之基本组件设计样式、声音体验。
然后做了一些性能参数:群友表示上网本渲染 WebGL 比较吃力,于是加了一些调整草数量的选项、画面分辨率的选项。因为有朋友表示倾向复古画风,所以针对低分辨率渲染额外增加了一个「像素化风格」的开关。
这里的声音体验是我非常喜欢的,按下那个开关时会有非常轻脆、魔法般的「叮——」声,画面瞬间变成复古风格,整个变化的体验非常饱满(也有可能是我自己很吃像素画风所以心里多了点戏)。
最后,加了个主题系统,因为我希望把画面风格作为训练者配速的一种提示,画面如果变得比较阴森那么你就得快点跑了。
这一块做得比较得意的地方是,渐变的动画用的是 Material Design 的 HCT 色彩空间,所以颜色的过渡非常漂亮。如果你玩 Story Mode 的话,差不多二十多分钟的时候会播一下这个动画。
打开调试器并且打 themeId.value = 'dark' 以及 themeId.value = 'clear' 也可以徒手切换主题(至少现在我还没把调试开关撤掉)。

看图你可能会发现刚开始的时候文字可读性之类的做得并不好,但是在做的时候基本思路还是「先解决有没有再解决好不好」,先把基本控件大概的样子定下来,后面再细调具体参数。
反正到第五天整个东西已经很可用了。前面讲的调试器、修色彩空间也是在这天做的。
至此,整个项目的基础建设已经全部做完,五一假期也过去了。
开始面对真正的业务逻辑
Day 6 ~ Day 10
正式开始处理故事模式了,原本以为有做基本操作的经验,一个简单的时间线功能应该不会很复杂,但事情比想象当中的要复杂很多。
最一开始的事件定义都很简单,跟密码学那些项目的套路都差不了太多,第一个剧本虽然写得磕磕绊绊但东西还是写出来了。就在音频做完,要开始搞媒体播放集成的时候,我才意识到大麻烦来了。
那段事件几乎是连续熬夜的状态,每天都在修 Phonograph 这个库没做完的重构。
先来讲一些背景知识,在浏览器中播放音频一直是个麻烦事。Chrome 要求用户至少与页面互动一次才能播放音频,Safari 则要求与每个元素互动一次,并且必须是同步的。Firefox 桌面端和移动端的限制策略则各不相同,这些限制让音频播放变得非常复杂。
为了应对这些问题,我们可以使用 AudioContext API,它原本是用来做「网页钢琴」这类应用的工具,本身发声过程不受权限模型影响,只需要在同步调用栈里面把 Context 激活就行。
虽然这个方案有效,但它会把所有音频解码成 PCM 格式存入内存,播放长时间音频时可能会导致内存爆掉。Rich Harris 提出了一个解决方案,将 MP3 文件的各个帧拆开,做成数据流,一块一块地喂给 AudioContext,这个库叫 Phonograph。
如果你看过这个库的源代码就能理解,写这个库的时候 Rich Harris 并没有特别擅长架构之类的事情,跟 Svelte 和 Rollup 的工程质量相差甚远,整个库存在很多问题。限于时代背景,Promise 还没有广泛应用,所有事情都通过 Event Bus 处理,导致业务逻辑非常散乱。音频的解包、下载和播放管理糊在一起,让整个库的逻辑非常不清晰,要往里面加一些功能或者修里面的 bug 也变得很困难,修掉一个 bug,就会冒出几个新的 bug。
我一年前曾经对这个库下过挑战,想把整个架构理干净,但是拆的过程中搞出来了很多问题,也搞散了曾经几个 bug 叠出来的 feature。经过几次放下又拾起来的过程,精神状态实在扛不住最终还是把这事情放下了。但是历史就是一个车轮,挖完不填的坑最后还是会回来找你,这不又要处理音频播放了,于是就发生了这第四次的爆肝熬夜。
尽管解包和播放仍然有耦合,但文件下载和针对 MP3 格式本身的的处理逻辑全都被拆干净了,也为后面添加新格式支持提供了空间。
整体上来讲,整个重构工作在做的事情是把基于事件的逻辑机制移除,换成基于 Promise 的异步编程模型。
重构后出现了很多很烦的问题,比如音频计时不对,初次拆包的流程跑不通,网络速度不够快的时候解码出来的文件会膨胀,DeMux 的过程会卡死。
最一开始真的是修到绝望,不管玩命 console log,还是打断点看变量都看不明白究竟出了什么问题。后来本着「工欲善其事,必先利其器」的原则,把整个解析二进制的过程全都打到了 DOM 上,一点一点的分词,才发现重构的过程中犯了非常多愚蠢的错误。
但好在最后这一伟大的历史伟业被完成了。因为根本看不太懂 Rich Harris 当年写了什么,所以花了一些时间用 GPT 整理代码文档,梳理原有的业务逻辑。只能说对于工作记忆容量有限的 ADHD 患者来讲这真的是省了非常多的脑细胞。具体地讲,它可以把非常复杂冗长的业务流程整理成列表,我不需要在脑子里面虚空连连看,对着它输出的文档做排查就好,这是很不错的调试体验。
Day 11 ~ Day 12
整个双休日,有机会花大块的时间做一些新的核心机制,这两天最重要的进展是实现了配速条。
这个东西看起来简单,但实际做起来非常讨厌。CSS 的渐变语法挺变态的,写起来很折磨人。周六一整天时间什么都没做,全都在写这个配速条的渐变规则。
配速条的设计大致是这样的:它是一个垂直的拖杆,两边渐变淡出,中间的指示器代表你现在的配速位置。拖杆上会通过红色区域标示出训练者的配速要达到什么范围。只要配速落到红色的范围,就会开始「掉血」。标红的地方有可能在上面(限制最高速度),也有可能在下面(限制最低速度)。
整个拖杆是用一整个 CSS 渐变实现的,两边「渐变淡出」的需求让语法上变得很复杂,如果配速标记红色区域卡在了渐变中间,就需要加条件判断改变渐变的绘制逻辑。
经过一整天的折腾,被 Gradient 语法疯狂鸿儒一天之后,整个东西搞出来了。「效率不高」的主要原因还是对 CSS Gradient 的语法不熟悉,加之刚开始为了做实验,徒手拼渐变的字符串,一点封装都没做,代码很丑。为了让 Code 变得优雅一些,来来回回试了好几种写法,最后把它封装得好看了一点,这个过程很费时。
第二天给配速条绑定逻辑。做了一大堆扣血的逻辑,还写了一个新的 shader,这个 shader 会在扣血的时候,给整个画面添加横向随机抖动的 glitch 效果。
虽然可以用现成的 shader,但我觉得现成官网得实现太复杂了,又闪又跳让人看着很不舒服,还有可能导致光敏性癫痫(参考 3D 龙事件),我只想要那种沿着一条横线随便抖两下的效果。
我怎么可能会写后处理 Shader(?),于是乎把官方的 Copy Shader 模板和需求喂给了 GPT, GPT 给了我一个大致可用的版本,虽然里面还有一些 bug,但核心功能都实现了。我在上面简单修了一下,比如调一调 uniform 和 glitch 规则,效果就有了。
赞美 GPT。
剩下的就是接各种后处理效果,比如调颜色、加噪点、加暗角等。把这些和血条的数值绑定在一起,如果你进入了过低或过高的速度,按照剧情设计就会开始扣血。扣的血越多,画面就会变成老电影风格,暗角会越来越黑,可视区域会变得越来越小。

如果速度不够,画面会抖动,Joy-Con 也会震动,画面中的血条和配速条会同时变红,给用户警示。
但我觉得这块做得不够,Joy-Con 的震动根本感受不出来,可能还需要具体调一下震动的频率和强度。
另外,在上机实测得时候,玩了 20 多分钟后发现卡得不行,后来发现是缓存泄漏导致的,考虑到算三角函数这种事情也不应该加缓存,于是把这块的逻辑去掉,第一次完整的故事模式实测就完成了。
参与测试的群友觉得跑步速度太快时,步数检测算法会变得迟钝,所以又加了一个叫 Sensitivity 的选项,可以调低检测的灵敏度,更容易触发检测。当然,这可能会导致一次性检测到太多步数,但这完全看个人喜好。
Day 13 ~ Day 16
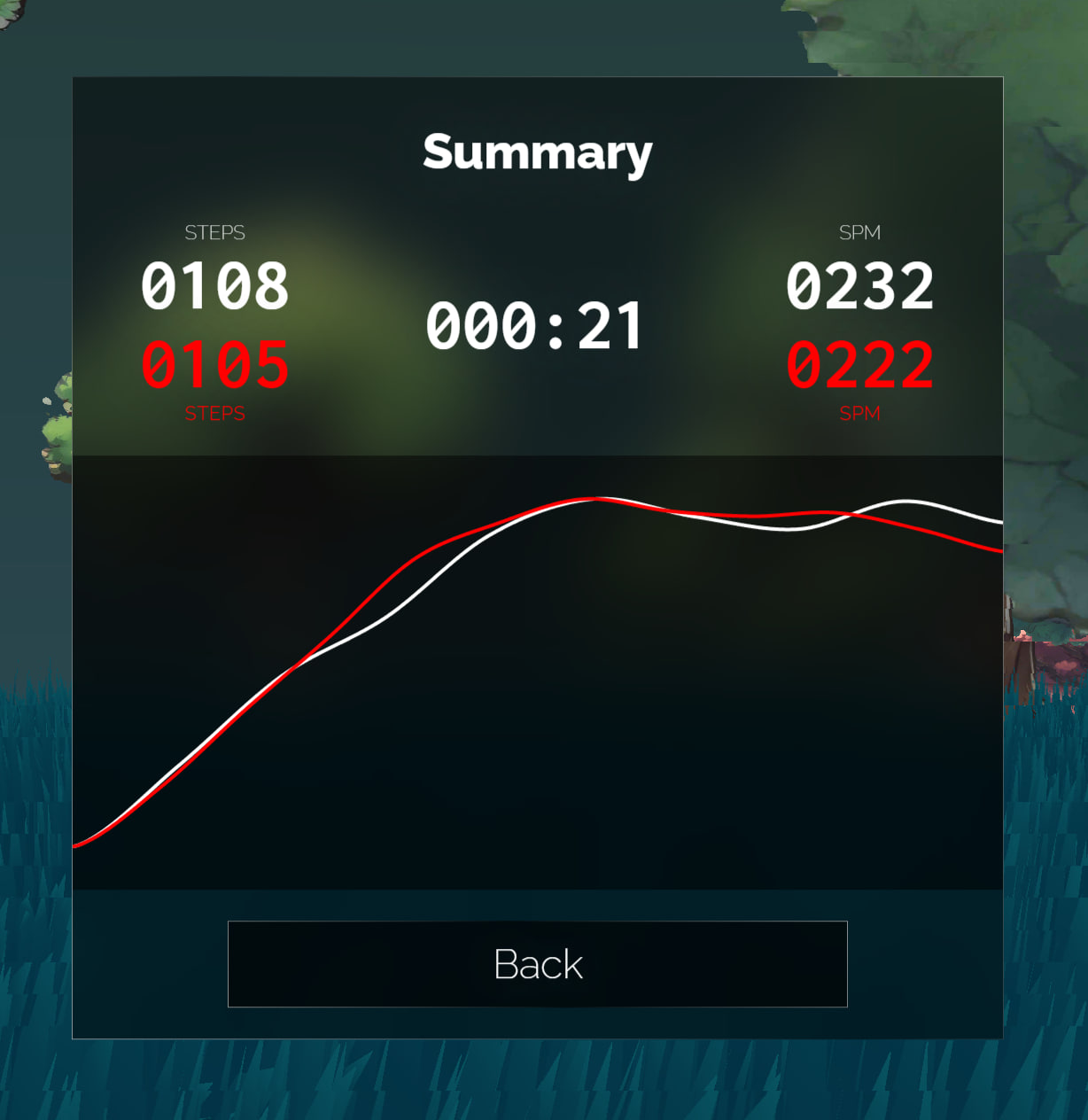
这几天的核心开发任务是做运动统计。训练界面的左下角多了了一个「Finish」按钮,点击后会停止计时,并展示一系列的统计指标,包括 SPM(Steps Per Minute)、运动时间。
因为是原地跑步,所以很难统计用户「跑了多少米」因此直接用 SPM 当指标是一个比较直观妥当的选择,当然也可以用身高数据做一个转换,不过这涉及到很多运动科学的知识,不是现在应该做的事情,于是作罢。
为了把整个运动过程的数据可视化出来,做了一个发光曲线的动画效果,我对它的描述是「像螢火虫一边飞一边拉出荧光屎的特效」,这个形容成功的让群友们生出了一大堆草。

另外一个很有趣的点是,我自己在用这个程序训练的时候顺便开启了 Fitbit 手表的运动记录功能,手表统计出来的总步数是 6000 多步,但 Alice Run 统计出来的总步数是 9000 多步。这也说明,用手机或者穿戴式设备记步数不如直接绑在大腿上记步数准确,而这个准确性是非常必要的。因为屏幕当中的所踏出的每一步都和现实当中的训练者同步,如果你跑了一步,里面的人没跑,会产生很大的挫败感。所以,「想用手机当作传感器来做步数统计」的需求被搁置了。
这段时间还做了一个图片 Transition 的功能(但最后没有实装),脑袋里面想的画面是,当画面色彩发生变化的时候,草地上的树最好也能跟着发生变化。比如一个寒冷的剧情,树最好是蓝色的,挂霜,这样跟整个背景色彩更加契合。
抱着这个想法,我查了很多用 THREE 实现图片转换动销的实现和教程,并且找到了一个我脑中最理想的方法,图片变成点云,散到天上,一边散一边变色,最后聚回来变成一张新的图。就像把沙子撒到水里一样。

能找到的实现有两种,一种是把图打成大量的三角形,然后用库来做动画。这个方案被我打枪的原因是我这个程序里面的树真的有很多,如果要做成粒子特效的话三角面数量一定会爆炸,而且几乎没有优化空间。而且范例工程里面用的库已经非常老,不被现代的 THREE 支持了(对,THREE 很常 Breaking 而且不遵循语义版本号),而且他们用的 GASP 库,协议真的不好看,所以这个方案被搁置。
另外一个方案是做成点云。但现在 Web 上用点云做视觉效果都会假定相机视角固定。一旦人离点云的距离变近,点和点之间就会出现缝隙,这个肯定是不可接受的。而且处理海量顶点时,渲染负担会不会太重也是一个需要考虑的问题。
最后我选择的做法是把一个平面变成数个平面,当动画开始播放的时候计算一下这个点离哪个平面的距离最近,然后把图像渲染到这个平面上,不在这个平面上的像素就 discard 掉不做任何渲染。

最后做出来的东西立体感的确都挺好的,但是因为用的噪声函数的性能很差,需要把整个噪声烘焙成贴图否则 GPU 压力太大了。加之之前树木渲染的设计不够好,为了控制 Z 轴选择了 discard 透明像素的方式打破了渲染管线的优化,应该把 Z 轴排序优化再好好做做。
这两个东西加在一起的开发成本不算低,而整个项目的「热情燃烧度」基本已经到头了,考虑到时间和心理成本,这个需求就先被按下去了,如果后面社区对项目的反馈比较好的话再来做,没有的话就先不做了(趴)。
最后是一个比较酷炫的东西,故事选择界面。
鼠标向左划的时候列表会向右滑,有一种「列表迎着你撞过来」的感觉。这种设计比较适合列表长度超过屏幕宽度,又不想做点按滑动的情况。说实话不太好做,算公式的时候整个人都很想死,GPT 也给不出来正确的公式,所以花了很长时间做调整,好在最后做出来了,效果也挺好的。
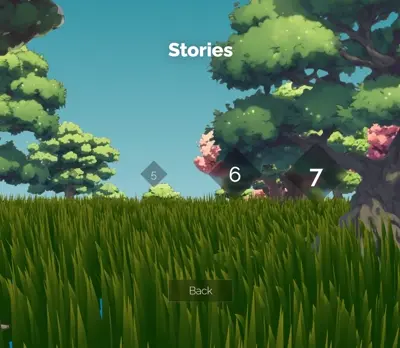
Day 17 ~ Day 21
调路由,做多个故事选择的路由支持。
顺便把多人模式做了。画面右下角多了一个连入第二个控制器的按钮,这样可以加入另外一个训练者和你一起跑步。 如果你没有朋友还想可悲的两个人一起玩,可以右键 2P 按钮激活虚拟朋友机器人模式,它会和你一起跑,甚至假装自己一会快一会慢,让你产生自己 18 岁在夕阳下跟对象奔跑的幻觉!
训练机制上,一个人扮演的是 Alice,另外一个人扮演的是「未知的恐惧」。P2 跑的越快,画面就会越昏暗,P2 的速度是 P1 需要跑的最低速度,如果 P1 跑的比 P2 慢就会掉血。
原理上来讲应该是 P1 血掉光了就 Game Over,但后来我反思了一下自己的产品设计哲学,决定把整个「游戏失败」的设计全都拉掉,至此没有任何一处游戏会「失败」了。
一方面是懒得实现这方面的功能,另外一方面则是心理层面上不想给训练者造成太大压力和挫败感。速度不够画面就会变黑已经是一个足够大的心理压力,如果在这个压力之后给一个「失败」的惩罚很容易让训练者退怯(至少我是这样)。个人认为实在没有必要在这方面打击训练者,所以最后就不加 Game Over 的设定了。
也顺便整理了一下菜单,把 Joy-Con 的调试界面、Sensitivity、是否开启 Bot 模式之类的设定都合并进了 Joy-Con 的设定菜单里,这样 Settings 界面变干净很多。
这个设计也给后面的联网模式留下来了一些空间。其实当时的确是想做一个多人联网的模式,有很多复杂的想法,比如说不对称团战之类的。但是产品角色本能的成本意识让我感觉这东西不可以做的这么复杂,而且实现的路径也不可以这样陡峭。所以最后画了个小一点的饼。如果后面真的做联网模式的话,可以让参与联机的两个人互为 P2,共同跑 Infinite 模式,这样工程复杂度上面会小很多,基本的陪伴感也做到了。
除此以外也规划了「插旗模式」这个玩法,算是实现多人模式路径上面的一个副产物。整体的构想是把任务划分成不同的组别,10 分钟、20 分钟、40 分钟、60 分钟。每个组别下面有 36 个 Slot。每个 Slot 上面都有一个「最佳训练记录」,训练者可以挑战这个记录,如果成绩比已有记录好的话就算「夺旗成功」,可以把自己的旗子插在这个格子上,等下一个人去拔。
挑战的过程和 2P 模式比较像,已有的挑战录像会作为「未知恐惧」陪伴训练者一起跑,只要挑战的过程中 HP 没有归 0 且平均速度比被挑战的记录高,就算挑战成功。
这个记录可能几个月会清空一次防止过于变态的成绩一直霸榜。
但这两个模式在第一版都不会更新,如果你真的很想要这个功能请敲碗(
Day 25 ~ 26
实现了一个故事线可视化工具。
一个剧本 41 分钟,完整播一遍所有的音频也得 10 分钟打底,调试剧本实在是一个很地狱的过程。所以花了点时间做了一个工具,可以快进整个故事,这样我就可以一步一步地看故事是怎么发展的。
顺便用找了个用来排日程的库,把时间线画出来,这样能比较清晰的看到事件的发生顺序。简单调了一下样式,让它跟我的系统能够接在一起。

之前本来想做一个故事编辑器,允许任何训练者都设计自己的故事和训练方案,但考虑到这个开发成本实在太高了,在没看到真实需求之前不应该轻举妄动。所以姑且做了这个「半套」调试工具给自己用,暂时也算是足够了。
憋不出来的故事线
Day 27 ~ Day 39 中间闹了一次胃肠炎,有三四天几乎是失能的状态。剩下的时间都在憋剧本还有做角色独白的语音。
剧本撰写
写作和写代码不一样的地方是,代码可以写得好或者写的不好,但是剧本写不出来就是写不出来。哪怕有 ChatGPT,有 Claude,有各种大模型,但是如果脑子里面想不明白自己想要什么,模型还是没用。创作依然是一项需要深思熟虑和不断探索的艺术。
GPT 在整个剧本创作的过程中,起到的作用更多的是一个启发工具,帮助我一点一点地把脑子里的线头理干净。但老实讲最后写文章的时候。还是得自己一点一点写。
模型方面,我一直觉得 Claude 的人文素养比 GPT-4o 高。
GPT-4o 是一款强大的大语言模型,它能够帮助我拼凑信息,分析模式,但却无法提炼出我想要的和文学创作有关的核心信息。
与之不同的是,Claude 给了我更多的启发,让我明白了剧本的大致方向和缺失的能力。哪怕写到中后段,我自己也不知道自己究竟在写什么,我究竟欠缺什么背景知识才写得这么难受。但 Claude 给了我很多启发。
下面是 Claude 对已有剧本的梳理。
这几段独白通过一个叫「爱丽丝」的人物的视角,描绘了一个广阔、神秘而令人焦虑的草原世界。每一段独白都有一些共同的特征:
- 重复出现「爱丽丝,快逃」的声音,营造出一种紧迫感和未知的威胁。
- 对现实世界的怀疑和对自我身份的迷惘,人物对自己是谁、为什么在这里、要逃离什么都没有头绪。
- 对生命的本质、人生的意义、宗教信仰等哲学命题的思考和探讨。
- 偶尔出现一些物品(如照片、贺卡、吊坠、小刀等)暗示了一些线索,但又很快消失。
- 环境的戏剧性变化(如火焰、雷雨、枯草等),增添了神秘感和不安全感。
- 对亲情、友情、人性的质疑和想象,试图从中寻找答案。
- 结尾部分重复出现「无尽的奔跑」和「诅咒」的说法,暗示这是一个没有尽头的循环。
如果一位作者想要模仿这种风格写作,需要具备以下能力:
- 能够运用富有想象力和诗意的比喻性语言描写场景。
- 对哲学命题和人生意义有自己的思考和见解。
- 能够描写环境细节并赋予象征意义,创造出一种神秘而不安的气氛。
- 对人性和人际关系有自己的理解和体会。
- 能够巧妙地使用悬念和反复,营造出一种循环往复的感觉。
- 具备一定的文学修养和写作技巧,能够运用恰当的修辞手法。
总的来说,这些独白具有浓重的存在主义色彩,富有哲理且想象力丰富,给人以迷幻般的阅读体验。要模仿这种风格并非易事,需要具备相当的文学才能和思想深度。
「不知道自己不知道什么」永远都是最恐怖的状态和痛苦的源泉。在剧本创作过程中,我自己就陷入了这样的困境,无法准确表达想要传达的信息。
所以最一开始的摸索过程都是,我先写一个开头,然后让 GPT 输出十几个可能的后续,我从里面找一点可能的方向,然后在上面剪切,修正,补充。接下来再喂给 GPT,继续撰写。
通过这样的互动,剧本创作的方向逐渐明朗。尽管目前的剧本质量依然不尽如人意,但至少几个模型轮番上阵给了我很多可以改进的思路,如果后面有机会重写剧本的话,质量一定会比现在好吧(笑)。
角色独白的制作
尽管剧本的原稿使用我的母语撰写,但真正实装到系统的时候用的是日语。其中的理由很难用语言表达清楚,只是觉得这个剧本的结构还有「阈限空间」风格的场景结合,呈现出来的内容状态,只适合使用日语做配音。
氛围方面的参考来自这季的新番《Wind Breaker》和《迷宫饭》。里面有几段纯角色独白,跟我理想当中的氛围塑造是一样的。
我必须要承认,敝人完全不懂日语,如果没有 GPT 做翻译的话,这个创作需求肯定完全做不到。至于如何判断翻译的好不好,我只能把输出的文本喂给 Google Translate,让它用语音的方式念出来,然后靠「语感」来判断了,我承认这有点需求搞纲但能力不行,但好在最后出来的效果还算能接受。
所有的角色独白的制作都是用 ElevenLabs 做的,个人经验是:可以的话不要用 ElevenLabs 生成任何日文内容。
ElevenLabs 的多语言模型并不能手动指定语言,全靠模型自己判断。但日文文本中是有一定比例汉字的,同样一个汉字在中日韩语言之间的发音并不相同,只是共享同样的文本编码。
在这个情况下,一个多语言模型语音合成模型的上下文感知能力如果不强,就会出现乱读的问题,如果汉字在假名中间,可能就会按照日式汉语来读。如果文本开头是汉语,整个文本的朗读可能都会崩掉,不光前面的字乱念,后面的内容也会变成乱读,因为模型根本搞不清楚自己在读什么东西。
比较明显的是,如果一句话的开头包含「昔々」、「日々」、「人々」大概率都是读不出来的(成功率几乎是抽奖)。
当时我不知道如何处理这个问题,只能不断地重试,最后找到一个勉强可以用的版本。
然而完整过了一遍之后,发现效果还是不理想。研究了好久后,发现可以将汉字全部换成假名,然后再进行语音生成,这样效果就好了很多。当然这件事情看人品,有的时候把整个文本都换成假名,效果反而会变差,这个时候可能把前面几个字的换掉效果会更好一些。
另外一个问题是,如果一段话太长没有加标点符号,Eleven Labs 可能无法正确断句。因此需要注意,必须要增加了一些顿号和逗号,以控制语言节奏,生成出来的语音才算可以勉强使用。
这一块断句的设计也都交给了 GPT-4o,我的提示词是:
这句日语太长了,读起来很拗口,请尝试通过添加标点的方式将其简单切分,以修正这一问题。当然,有一些情况是不管你怎么折腾它都读不明白,这个时候就只能做同义句改写,真的很折磨人。
另一个经验是,Eleven Labs 的音色生成效果也非常抽奖。对于有些音色,输入的是日文,读出来的语音介于法语和日语之间,就像一个外国人在讲日语一样。
在这种问题上浪费了很多时间,最后只找到了一个可以用且让我满意的音色。因此后面我决定不做多角色配音,先把基本的内容上线,后续再考虑多角色配音的问题,不然打这个泥巴仗永远都打不完……
配音管理
因为需要将音频和脚本的编号以及中英文、日文的对齐。如果不对齐,后续的编排程序和事件编写会变得非常痛苦。所以找一套管理工具就变得很重要了,尽管尝试了很多工具,虽然它们能部分解决问题,但整体体验还是不尽如人意。
为了解决这个问题,我想自己可能需要一个能拉出表格且兼有多媒体管理功能的软件。这样当出现手误时,我就可以快速在表中查找出问题的文件,而不至于盲猜哪个文件出错,一个一个去听调试,这样的体验非常不好。
我尝试过 Excel,但它的单元格里不能插入媒体文件,Word 在这方面也不行。之前的脚本都是在 Word 里写的,基本的管理功能都可以实现,但要插音频文件,感觉就像在 PDF 里做一个小游戏一样,荒谬且不显示。
后面也试了 Microsoft 的 Loops,但它的表格里也不能插入媒体文件。多维表格是可用的,飞书的多维表格和飞书文档也能实现,但我不愿意使用云服务的工具,觉得很不方便。
后来我发现了 Obsidian(黑曜石),这个软件达到了其他笔记软件无法企及的完成度,并且可以很好的完成我要做的事情。
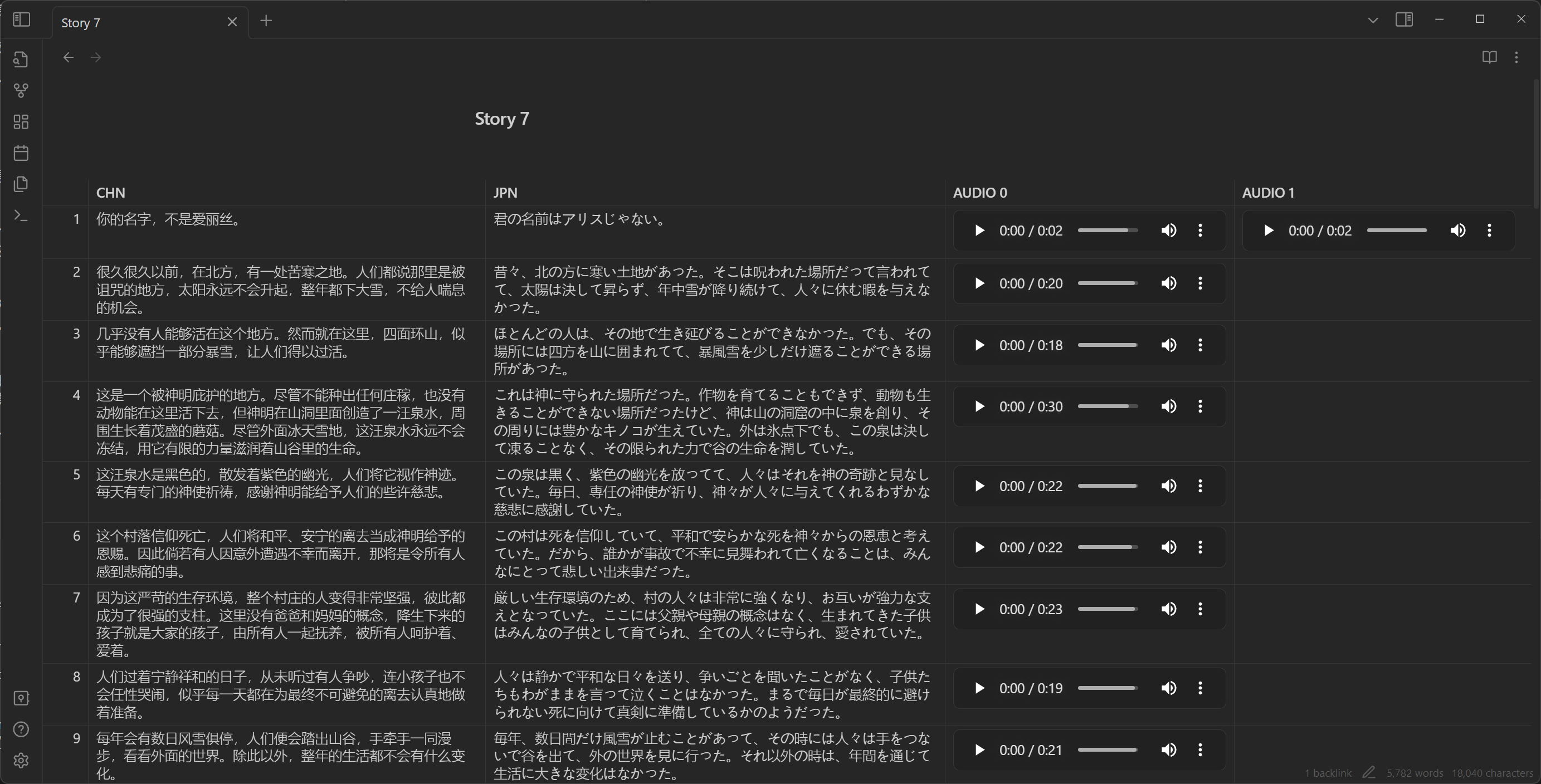
配音管理方面主要用了几个插件:
- Minimal Theme Settings:主题设置里能把表格拉成全宽,这样能放得下四列内容;
- Iconize:给文件加上图标方便一眼就能找到我想要的文档;
- Advanced Tables:表格管理,徒手管理 Markdown 的表格真的很痛苦,有了这个插件至少行列调整的时候不用盲着摸索了,挺方便;
- File Hider:因为文本文件全都内嵌到了文档里,所以文档库多了一大堆音频文件,隐藏之后看起来比较干净;
- Folder Note:给文件夹加说明文件用的。
文档与结案报告
文档编撰
文档库里面主要有几份用 GPT 写出来的文档,用来归拢重要的设定信息。这些文档的是随着脚本的形成不断被整理出来的。换言之最一开始这东西要怎么做我其实没什么想法,一开始抓了个感觉,把我脑海当中的意向喂给 GPT,由 GPT 出几个可能的方向,再由我做调整和选择。
一切起源于我问甜老的问题:「ˊ_>ˋ 请问,有什么适合放在这种场景的故事么,一个无限奔跑的体感(游戏)程序,一边跑一边出故事这样。」
甜老:「问住我了,感觉可以跑团?真·跑,团,比如一百步刷一段剧情,然后一百步扔个骰子什么的,龙与地下城那种,编一个。」
按照这个感觉,加上我提供的一些原始设定(比如 Alice,草原,失忆,无限奔跑,有人催促快跑之类的核心概念定义)GPT 出了这么一份设定文档:
标题:《ALICE RUN!》
概述:在这个TRPG剧本中,玩家们将扮演Alice,一个在无垠草原上奔跑的小女孩。阳光明媚,鸟语花香,但是Alice的心中却充满了不安。每当她放慢脚步,就会听到一个声音在她耳边响起:“Alice! Run!!” 这个声音既熟悉又陌生,似乎带着迫切的警告。Alice不知道她在逃离什么,也不知道这声音的来源。玩家需要帮助Alice揭开真相,同时保持警惕,因为草原上的每个角落都可能隐藏着不为人知的秘密。
设定:
- 时间:不明
- 地点:一片广阔的草原,四周没有任何建筑物或明显的地标。
- 角色:Alice,一个看似10岁左右的小女孩,穿着简单的裙子,光着脚丫,长发随风飘扬。
规则:
- 玩家扮演Alice,只有在团长指定的情况下才能进行骰子检定。
- Alice的行动由玩家描述,但团长会根据情况提供环境反馈。
- 当Alice停止奔跑时,玩家需要进行一次“意志”检定,来决定是否能抵抗住停下来的诱惑。
- 如果玩家选择探索某个特定的地点或物品,可能需要进行“观察”检定。
剧情概要:
- 开始时,Alice在草原上奔跑。她不记得自己为何在这里,也不知道目的地在哪里。
- 玩家可以选择让Alice探索周围,或是继续奔跑。不论选择何种行动,她都会不时听到那个声音。
- 当Alice探索时,她可能会发现一些线索:
- 一块破旧的布娃娃,似乎很熟悉。
- 一串脚印,看起来似乎是成人的。
- 远处的一棵孤独的大树,树下有些东西在闪光。
- 随着时间的推移,天气会慢慢变化,阳光逐渐被乌云遮蔽,草原上的气氛开始变得压抑。
- Alice将面临选择:是继续探索草原上的秘密,还是试图找到回家的路。
- 在某个节点,Alice会遇到一个神秘的老妇人,她似乎知道一些事情,但是她的信息是模糊的, Alice需要通过对话来获取线索。
- 最终,Alice将揭开草原的秘密。这个秘密可以是一个科幻元素,如草原是一个模拟现实;可以是心理元素,如这是Alice的梦境或心理投射;也可以是魔幻元素,如草原是一个被诅咒的地方,Alice是唯一的解除诅咒的钥匙。
结局:
- 如果Alice揭开了草原的秘密,并找到了逃离的方法,游戏以她安全返回现实世界作为结局。
- 如果Alice未能逃脱,她可能会被草原永远困住,或者被迫面对一个更加恐怖的真相。
这个剧本的关键是保持悬疑与神秘,让玩家在探索中感受到既美丽又危险的草原氛围。团长应该根据玩家的选择灵活引导剧情,确保游戏体验既紧张又刺激。
甜老:「挺……挺牛逼的」
我有同感。
后面随着剧本的撰写,为了从里面提取规律,也陆续用大语言模型写了一些《写作风格指导》、《角色塑造分析》、《模仿建议》,有些用 Claude 写,有些用 GPT 写。
最后用 GPT 过了一遍所有已有的文档,写了一些文档导读,整个文档库就算建起来了。其实我自己没写几个字,但是我想要的东西全都有了。而且随着文档变多,脚本的创作思路也变得越来越清晰,相较前面的几个故事,最后面的两个故事质量明显有变好。这种被神奇现代魔法「兜底」的感觉非常神奇。
结案报告
结案报告就是现在你正在阅读的内容,自打一开始就想着,我这种 ADHD 患者、高考立体几何从来都没拿过满分的玩家能够通过各种当代科技完成这样的一个作品,是非常独特的体验。所以应当写一篇文章把这过程当中的每一个细节都记录下来。
于是那段时间我的电子日记全都变成了 Alice Run 的进度报告。
先来介绍一下电子日记(或者说电子口水),在我的 Telegram 频道里,每周我都会用语音录一些日记,记录一下当天发生的事情。短的五六分钟,长的三四十分钟。通篇不打稿,上下班走在路上想到哪里就说到哪里。
老实讲,每天能留下的文字量非常庞大,如果真的要我一笔一划写日记,可能记不下来这么多内容。所以录音日记是一个很好的形式。
后面为了形成系统性的文字记录(主要是为了可以搜索),就上了 whisper.cpp,做文本转语音,再用 GPT 去掉口癖表达再存档进 Obsidian,效果是这样的:
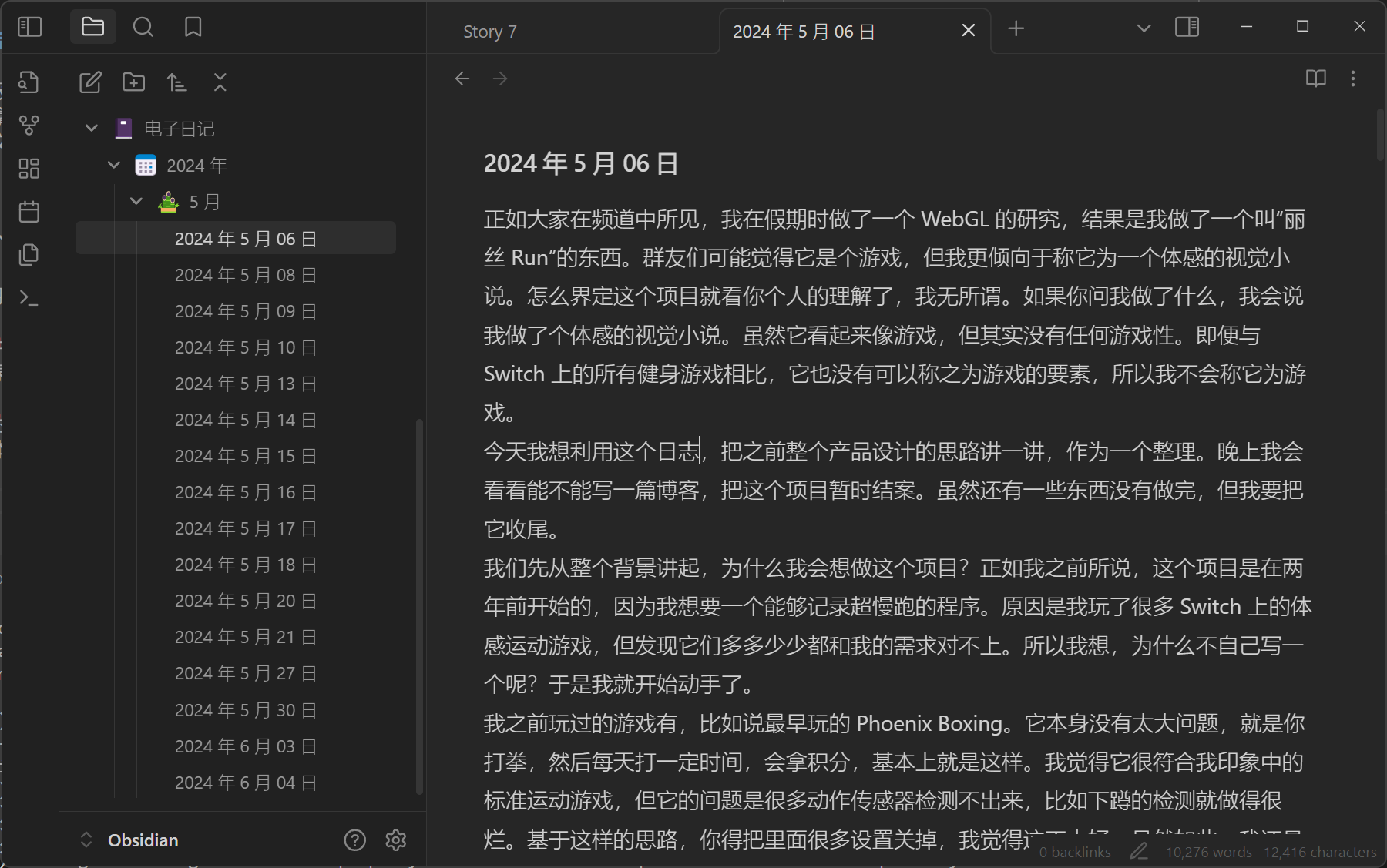
接下来实际撰写结案报告的时候,要做的就是把已经有的文本拿出来再做一次蒸馏,留下枝干内容就好了,非常方便。
结语
其实 Alice Run 是一个很怪的项目,我们把上面所有故事性的东西去掉,最后整个项目就的枝干就只有「训练者踏步,屏幕里面的人就跟着跑」、「有一点统计功能」的训练程序而已。甚至训练的痕迹也没有那么多。但对于我个人来讲这个项目的意义重大,它证明了新一代基于「AI」的技术,如何提升了这个这个世界的包容性。
一名不懂日语的读者,可以在大语言模型的帮助下读完一整本日文的书,完成日文脚本的撰写;一个对工业界信号处理一无所知的开发者可以在大语言模型的指导下设计出完整的步数检测算法;一名高中数学几乎没有及格过的数学白痴,也可以像模像样的写一些简单的计算机图形学代码;甚至在重构已有工程、修Bug、性能调优等方方面面,大语言模型一个完全不会电绘的人,也能用 Stable Diffusion 制作很多成熟的贴图素材;哪怕不擅长写作,大语言模型们也能耐心的一点一点指导你完成独立的作品,帮助你整理资料、撰写文档和报告。
对于一名「没有耐心」的 ADHD 患者来讲,在十年前,这当中任何一步都有可能杀死我的创作热情,但时至今日,仅仅需要一个多月的时间,一个纯粹的新手就能完成一个看起来像模像样的作品。
在从前,一名合格的开发者需要的核心能力包含:语言能力、逻辑和数论。虽然不同领域的开发所对这三项需要的程度不同,但倘若有一个是瘸腿的,职业生涯天花板就会变得极低。
而当下我所看到的图景是「自己的短板被兜住,只要有想法就可以自由去做」的安全感。我们正在接近一个「任何人都可以做任何事」的世界。在我还在上高中的时候,曾经为 Node Webkit 的出现感到欢欣鼓舞,因为对于开发一个「可用的」桌面程序,那些「艰深晦涩」的开发知识在某种程度上变成了可选项。而转眼十几年,这个门正在被进一步削弱。而在当下,最大的门槛可能只剩下:脑子里要想清楚自己究竟需要什么,想象当中的产品究竟是什么样,也就是精确、妥善的表达。[1]
回到项目本身,我为什么要做这样的一个项目。其核心的人文理想也是希望达成一个「任何人可以做任何事」的世界,提供一种新的选择。一提到减重、锻炼,大多数人能想到的可能是出门,去户外运动,大汗淋漓,肆意挥洒的阳光和青春。但这些刻板的想象将非常多性格内向,或身体素质不够硬的人挡在门外。以我个人为例,平均两个月要闹三次病,每次想要重新恢复运动习惯,没几天就躺在床上变成了死人。
对于那些不能被套进「刻板印象」的人,我希望能够提供另外一种更加温和的选择,希望每个人都能以自己的步伐自由的探索这个世界。
哦,对了,我好像忘记贴项目地址了。
源码:https://github.com/losses/aliceRun
以上就是本次的结案报告,莉莉爱你 ♥~
但一些偏底层的工作还是不能全都用大语言模型暴力推过去,逻辑链条越复杂的任务,大语言模型越搞不定,这一点在可以预见的未来不太可能发生改变。 ↩︎

Loading comments...