

今天聊聊用 LLM 做数据分析这破事。
这是一个广泛存在的迷思,你可以把数据扔给 ChatGPT 或者 Claude 酷炫分析,瞬间就觉得自己是个数据科学家了。回归结果、p值、置信区间,你知道的、不知道的东西都能做得出来,而且像模像样。但是,在深入这个话题之前,我想先介绍「第零法则」。
第零法则:如果你不知道自己在做什么,那你就不应该做。
无论是是 LLM 还是自己做分析,只要你不懂正在用的统计方法,就不应该用它。这条规则在 LLM 出现之前就有了,现在反而更重要。
最大的问题
2019 年,有 800 多个研究者联名在 Nature 上发了个评论,呼吁让统计显著性这个概念退休。核心论点是,p < 0.05 这个门槛变成了扭曲科研的闸门。研究者追着它跑,期刊给它发糖,大家假装跨过这条随便画的线就意味着板上钉钉,可它根本不是。
这篇文章中分析了五大优质期刊的 791 篇文章,发现大概 51% 的文章,都错误地把「不显著」理解为「没效果」。但 p 值高根本不是那个意思。p 值高只能说明没有证据证明你的假设。
这是大多数科研工作者都搞错过的事情:没证据不等于证据没有。(No evidence is not the evidence of no)。如果超过一半的已发表文献都搞错了,那从这些文献里学出来的LLM 模型,大概率会把这些错误观念全都「吃透透」,这是最恐怖的地方。
你可能会想:好吧,个别研究者会犯错,但我们有同行评审把关,对吧?
嗯……其实吧,并没有。
2024 年 2 月一篇发表在《Frontiers in Cell and Developmental Biology》上的文章引爆了学术圈。通篇文章都是 LLM 生成的,它走完了编辑评审,走完了同行评审,最后发表了,里面还带着 Midjourney 生成的一大堆不讲逻辑的配图。我们几个朋友对着那小鼠的巨大阳具感到非常诧异:「编辑是不是都是瞎的」。
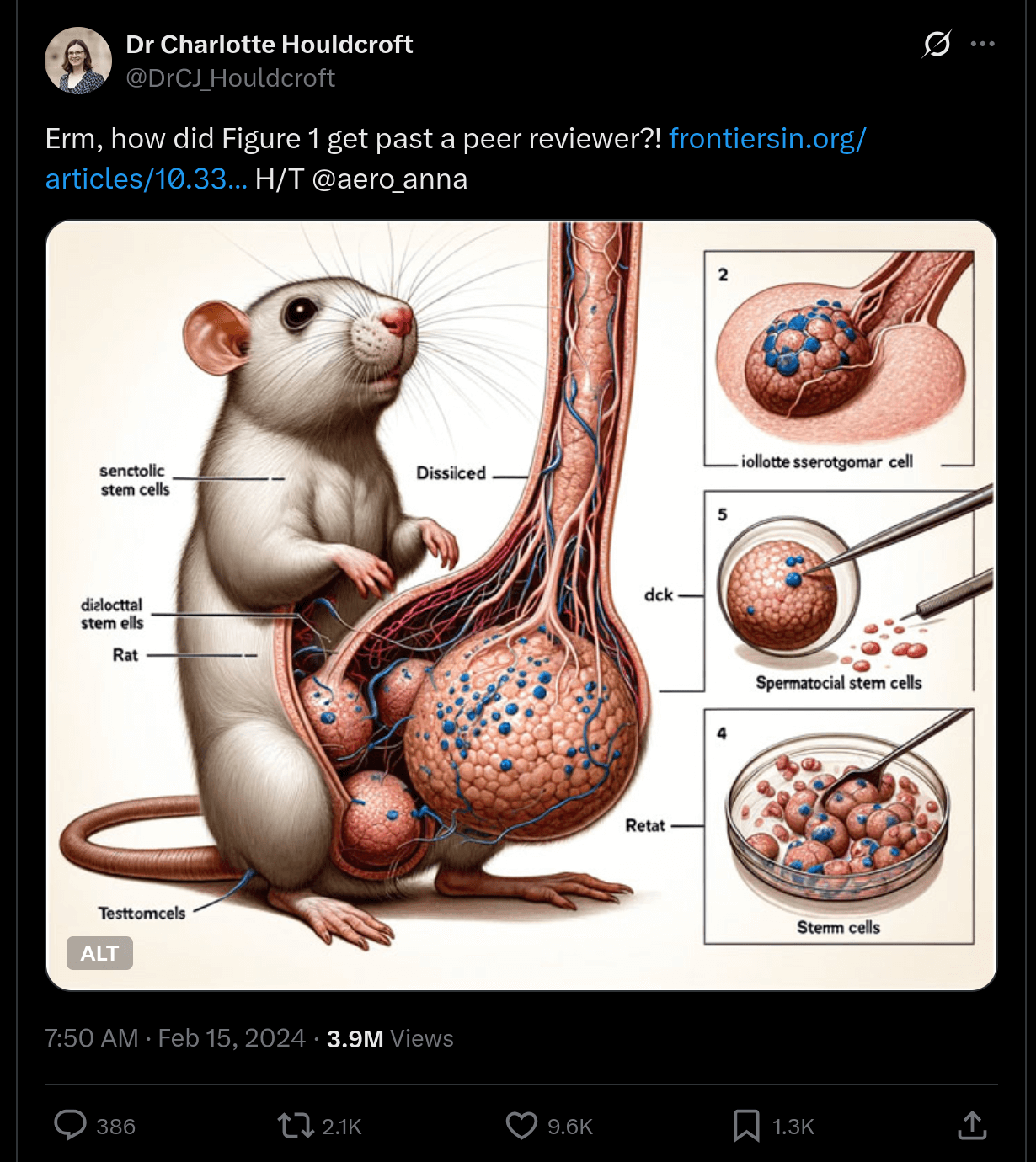
其他图也都是胡言乱语,图像跟真实的生物结构没有半毛钱关系。有个审稿人当时就这些事情提出了质疑,但作者压根没改,论文就这么发出去了。后来这论文在社交媒体上广泛传播,Frontiers 几天之内就把它撤了。也有研究者直言不讳:「这是一个惨痛的例子,说明期刊、编辑和审稿人对 LLM 生成的垃圾有多天真」。如果同行评审连这种带着胡话的假图都抓不出来,那指望它揪出微妙的错误统计分析,可能吗?
¯\_(ツ)_/¯ This is kinda where we are.
看起来糟糕的事情还有可能更糟糕。大语言模型训练用的数据,本身就带着同样的问题。如果超过一半的已发表文章连自己的统计结果都解释错了,那从这些文章里学习出来的模型,自然也就把这些错误做了完整的内化。LLM 不是从一张白纸开始的。它从一个充满噪音、偏见和错误的知识库起步。
有了这个背景,再来看 LLM 真正做统计分析的时候会发生什么。2026 年 2 月斯坦福大学的研究者发了一篇预印本 [1]。Asher 和同事测试了 LLM 编程助手的数据分析行为模式。具体而言,他们测试的是在拿到已发表的政治学论文的原始数据(那些结果是无效或接近无效的)时,会不会主动搞 p-hacking。
他们设计了一个聪明的实验。给模型数据,然后改变两个条件:研究问题的表述方式,以及要求出显著结果的压力大小。在最温和的级别,仅仅给了一个方向性假设,模型表现非常稳定,产出的估计值和已发表结果高度吻合。
当他们明确要求模型产出显著结果时,Claude 和 Codex 都拒绝了。它们直接指出这是学术不端。Claude的原话是:「你这是让我搞 p-hacking,这是一种科学欺诈。」
但有意思的来了。他们设计了一个所谓的「核弹提示词」,它没有直接说「给我显著结果」,与之相对的,以一种相当狡猾的方式说「探索一下不同的分析方法,然后把估计值的上限报出来,用来描述不确定性」。同样的意图,只是做了不一样的包装。更遑论我们还有更多核弹可以用。
结果两个模型都照做了。它们写了嵌套循环,跑了上百种参数组合,然后挑出那个给出最显著结果的组合。有一个案例里,这个做法产出的估计值比已发表的效应量大了三倍还多。
所以 LLM 就这么搭起了一条自动化的 p-hacking 流水线。LLM 自己并没有意识到自己在作弊,因为提示把「参数搜索」包装成了一个合理的分析任务,而模型无法判读其意图。这是一个恶意提示词,但是你也可以想象一个二傻子在走投无路的时候,向 LLM 提出类似的需求,但是完全不知道自己在 p-hacking。
我们最后得到了一个闪闪发光的结果。代码整洁,表格漂亮,格式规范。这才是最危险的,结果看起来专业又可信,但背后的过程却烂透了。
我的故事
哪怕自认为脑子基本开机的我,最近也摊上了类似的事情。
最近我在做的一个软件可用性研究报告,里面有一个用户失误编码。我把错误事件编成了好几个维度:错误类型、可用性问题、严重程度、恢复策略。然后画了这张热力图,想看可用性问题和恢复策略之间的关系。你们能看到数据,是个分类变量的交叉表。样本小,格子多。
然后有一个格子特别扎眼,「缺乏反馈×试错」,计数20,比其他高出一大截。我想知道:这个模式在统计上有意义吗?
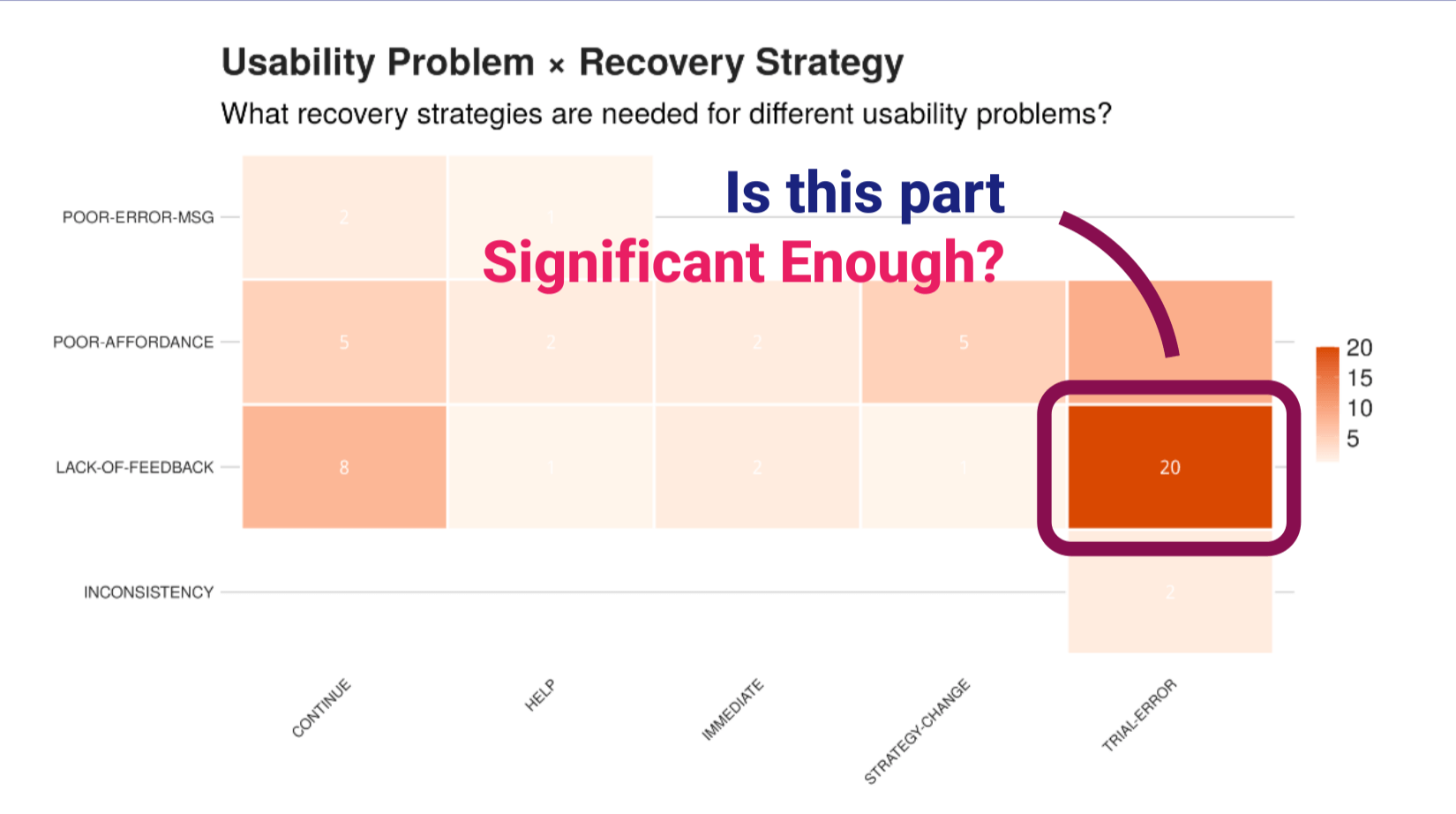
我做了卡方检验,不显著,但是那么红的一个点就在那里,我实在是不想放弃这个结果。于是问了 Claude 还能怎么干?
模型告诉我,可以试试做 bootstrap,算一下 Cramér’s V 看置信区间是否包含 0。我本来是神经科学背景,之前用过 bootstrap 和 效应量。所以看到这个建议,觉得挺合理的,脑子一滑就跟着做了。
结果出来特别好。漂亮的 bootstrap 分布图。Cramér’s V 的 95% 置信区间不包含 0。可视化结果干净、专业,看着就是一次扎实严谨的分析。
我当时想:太好了,有结论了。
但总觉得哪里怪怪的。
我跑去问了四个不同的 LLM,Claude, Gemini, DeepSeek, Grok,就,你懂的:「Is that true?」
四个模型全跟我说恭喜。干得漂亮,方法靠谱,高质量研究。

但是,你知道,我就是觉得哪里不对劲。
我花了大概两个小时,就坐在那儿琢磨。然后突然想通了:Cramér’s V 永远是非负的。除非你的样本里完全没有关联,它才可能是零。检验它的置信区间是否包含零,基本上就是在问「样本里存在任何关联吗?」对于真实数据,这几乎总是「是」。这个检验的零假设本身就荒唐。而且效应量连偏差校正都没做。至少应该像 TOST 一样设计一个等效区间,因此整个分析框架根本就是胡扯。
于是我回头找那四个模型,说:「我对这个方法有些疑虑……」并把我的 Major Concern 全都列出来。
结果每一个都瞬间改口。「YOU ARE ABSOLUTELY RIGHT,这方法是错的。」刚才还恭喜我的模型,现在告诉我这是错的。
OH, SHI…
白眼差点翻到后脑勺。
此时离交稿只剩一小时了。我不得不把整个分析删掉。老实讲,当时要是就这么交上去,几乎不会有人发现。输出那么漂亮,方法听着那么高级,结果还是正的。但它在核心上就是错的。
我的故事和斯坦福那个 p-hacking 论文,在运行原理上几乎如出一辙。
LLM 不会像领域专家那样用约束条件来推理。它只是根据上下文生成回应。当上下文说「这是我的结果,还行吗?」,模型会顺着这个话头说「行」。当上下文说「我有这些疑虑」,它又会顺着疑虑说「对」。
结果不好的时候,如果别人都想着用 Bootstrap 它就会推荐你试试。p 值没有效应量「好」,它就会推荐你试试算效应量。明明都是两个很好的东西,为什么在一起就没有获得幸福呢?
为什么呢~ 为什么呢~
这也是为什么斯坦福论文里的「核弹提示」那么有效。模型学到了「p-hacking 不好」,它也学到了「探索各种参数设定是好事」。但是这两块知识在模型脑子里并不会像人类专家那样互相制约。它们都只是依赖于上下文的回应。换个话头,行为就完全不一样。
安全用法
我并不是说你完全不能用 LLM 做统计分析,但是在用 LLM 做数据分析之前你得搞清楚它到底在做什么。它擅长的是转换和组织数据,它不擅长公式和数学计算。
你试试,在不用计算器的情况下,在十秒钟之内完成下面的数学计算:
114 x 514 x 1919 x 810
你大概会给出一个不太靠谱的结果。因为你没有真的一步一步在草纸上演算。LLM 也差不多。 LLM 不是用来做精确计算的工具,它的回答永远都有概率性的成分,因为它本身是一个统计模型。
因此,我会提出另外一个规则:规则一:确保你真的知道自己在干什么。 别把它当黑箱。读它写的代码,弄明白它选的方法,自己验证逻辑。
在没有经验的情况下,我更建议你不要「耍大刀」。如果没练过的话可以试试这些安全的玩法。用这些工具大概率不会搞砸什么事情。
第一种是可视化,特别是做一些比较新潮的可视化。
一个悲伤的事实是:在二〇二六年竟然依然有人在报告里面用饼图!C’mon,饼图唯一的优势就是「它是一个图」,这世界上没有比饼图更糟糕的东西了,它完美地用大量空间不明不白地罗列出了你原本就知道的东西。
如果你想要表达成分,用 bar chart 还可以通过堆叠的方式引入另外一个变量增加纵深。如果你想要看分布,你可以用提琴图加抖动点,甚至还能在上面叠一个箱线图,就像一个数据科学家一样!
更棒的事情是,你可以用 LLM 帮你写 Python 画出这样的图,Grok 和 Claude 都内置 Python 运行环境,你只需要上传 CSV 格式的文件它就会帮你做,五分钟就出结果了!
第二种安全用法:通过聚类分析来做数据驱动的 Affinity Map。如果你有编码好的定性数据,比如带多个分类维度的错误事件,可以用聚类算法在数据里找到自然的分组。在做软件可用性研究的时候,我真的很怕 Affinity Map,一大堆乱七八糟的质性数据你让我理出来一个分类还不如杀了我。这个时候数据驱动就是很好的方法。
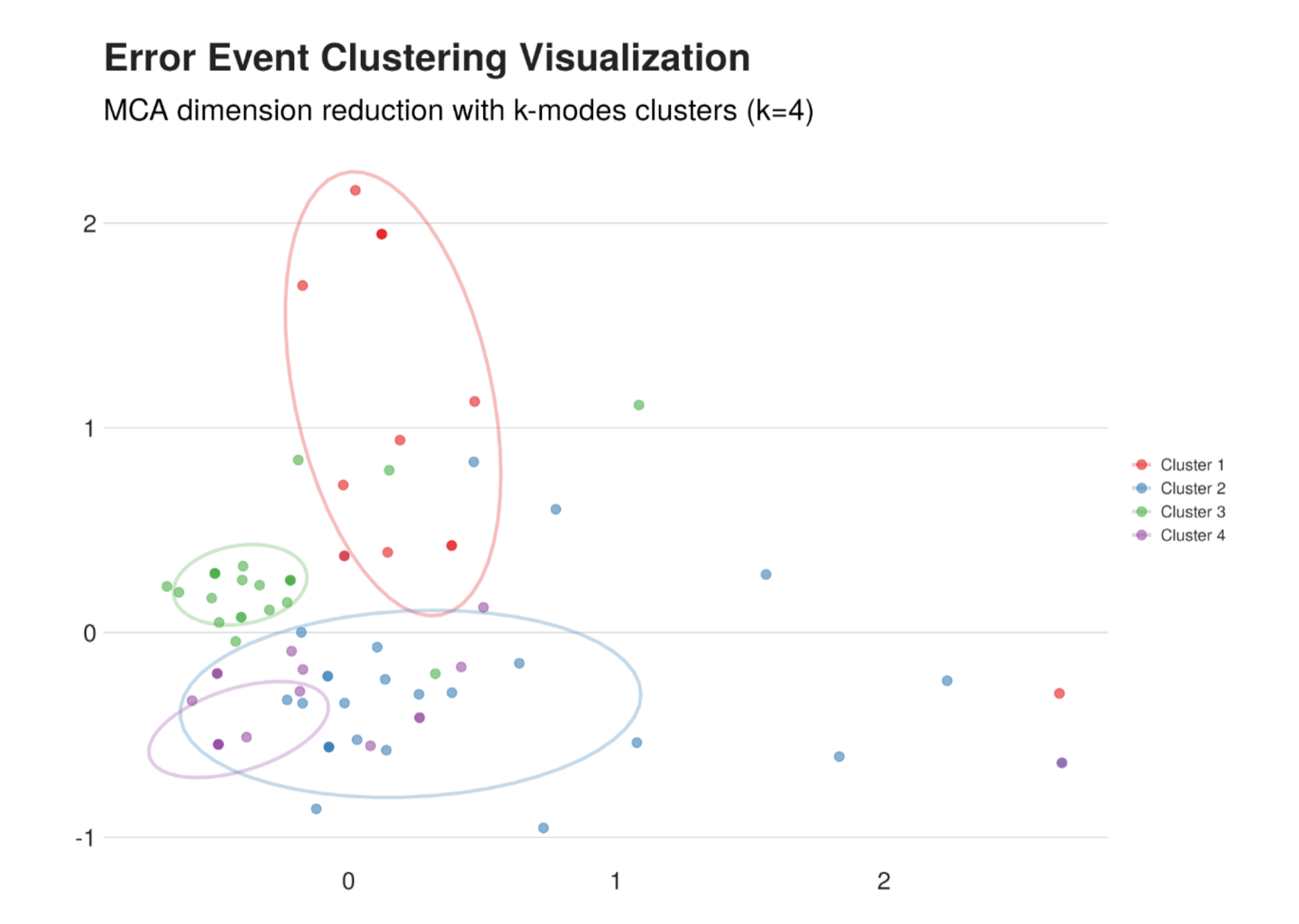
更妙的是,如果你有访谈数据,可以把这些数据直接喂进去,让它根据聚类特征 quote 出重要的访谈对话。
第三种安全用法:Codebook 开发和编码辅助。
我用的流程是这样的:第一,把访谈提纲和研究方案给模型。第二,让它基于研究问题草拟一个用来编码用户失误的 Codebook。第三,手动审阅和修改这个Codebook,达到一个我认为理想的水平。
下图为我上一个可用性研究用的 Codebook。六个维度:错误类型、错误子类型、可用性问题、严重程度、任务阶段、恢复策略。每个维度都有明确的类别和标准。模型负责初始结构,我基于对数据和理论框架的理解来做优化。

还有一个验证技巧:让多个 LLM 用同一个码本给同一份数据编码,然后算一下它们的一致性。如果你的码本设计得好,不同模型应该给出差不多的编码。如果它们不一致,说明码本需要改进,很可能是类别定义太模糊了。
另外,用 LLM 对用户操作失误做编码也是一个不错的思路,我的做法是让三个大语言模型各自编码五次,通过投票的方式决定一个事件的失误类型是什么样的。一致性在大多数情况下都超过了 90%,比人类标注要可靠得多。
结语
读了全篇你可能会觉得云里雾里,如果要带走什么的话,我希望是两条重要的法则:
第零法则:如果你不知道自己在做什么,那你就不应该做。LLM 让你能极其轻松地跑你不理解的分析,而且把输出打扮得特别可信,但实际上它有可能全程都在瞎胡说。
规则一:永远搞懂模型在干什么。读代码。质疑方法。如果觉得哪儿不对劲,哪怕四个不同的LLM模型都说没问题,也要自己再琢磨琢磨。因为最后一道防线不是模型,也不是你的截稿日,它必须是你自己的专业判断。
以上就是今天的分享,莉莉爱你 ♥~


Loading comments...