


我们常常以为,研究是一件收集数据的事。只要方法选对了,样本够了,问题问得准,结论就会自然从数据里长出来。好像研究者只需要扮演一个诚实的记录者,把观察到的东西如实呈现,工作就算完成了。
但如果你真的做过研究,你会发现事情从来不是这样的。数据不会自己说话。它只是静静地堆在那里,等着你决定它们之间的关系。你怎么理解它们,它们就怎么呈现自己。同样一堆数字,不同的人拿到手里,可以讲出截然不同的故事。有人看到的是混乱,有人看到的是结构,有人什么都没看到,只是把表格原样贴进了报告。
这背后的差距不在于数据本身,而在于看待数据的方式。
研究,特别是用于体验研究不只是一个简单的操作流程,它需要一种系统化的思维方式。你需要知道为什么要用这个方法而不是那个,为什么这两类数据放在一起会产生张力,为什么同一个现象从不同视角看会得出完全不同的结论。更重要的是,当数据之间开始打架时,你需要有能力在混乱里找到一条逻辑线,让它们重新开始对话。
今天我想就这件事和你聊聊我的拙见。
用户体验是一个综合而复杂的信息空间
我想邀请你从信息设计的角度重新理解研究框架的搭建,以及故事脉络的梳理。
- 数据就是简单的观察,它本身没有过多的思考。
- 如果我们多做一步,将几个数据胶连在一起,洞见就会浮现。
- 熟练的研究者能从多个视角观察同一个事物,这时你就能看到某种智慧。
- 当然,如果你不做研究而纯粹靠想象,那就是纯粹的阴谋论了。
这个跟 DIKW 体系[1]有点像,但老实讲,我是听了审稿师傅提了才发现这个框架的,如果你感兴趣的话可以读读 Wikipedia。

让我们先从简单的数据看起。一种常见的报告呈现方式是把散装的观测记录、简单的统计结果直接甩到报告上,最后灌上一些浮于表面的解释,就像报菜名一样。这样的报告在某种程度上转嫁了数据解读的责任,读的人需要花大量的时间做进一步的信息整合以及理解。但你知道,并不是每个读者都有那么多精力让大脑旋转起来,就结果而言,我们劳神费力创造了一篇无用的研究。
要改变这个局面,就要把这些数据真正连接起来。你或许早就知道了很多连接数据的方式,却没有意识到自己是在创造洞见。一些简单的描述性方法,像是用用热力图把两组数据叠在一起来看数据模式,用分组堆叠柱状图来看比例分布,用冲击图来看数据在不同模式下的流动。如果你愿意多花点时间,甚至可以进行更复杂的分析技术像是聚类分析。最后,专业的数据分析工作者可以试试有些危险但是更有力量感的方法,诸如方差分析、线性回归、卡方检验。这些技术让数据开始互相解释。




但如果你只有一个视角,洞见就会有它的边界。这就是为什么熟练的研究者会做另一件事:引入更多群体,让不同的人来看同一个事物。一个一般用户坐在电脑前面,对着软件或者网站手足无措,一脸茫然。他的每一个行为都能告诉你这个产品具体哪里涉及的糟糕,但是这只能告诉你不好用,却说不清哪里不好用、为什么不好用。这是用户的视角,真实、重要,但有其局限。这个时候或许你会想要邀请几个专家,他们受过专业的训练,理解用户体验设计的基本要素,它们能够看得出 Happy Path 在哪里,什么阻止了用户顺利的完成任务,他们知道构成良好用户体验到底需要什么要素。但专家也有盲区,一旦拥有了专业视角,就很难再退回到什么都不知道的状态,很难真正体会一个新手面对空白界面的那种无措。这堵无知之幕一旦升起,就很难降下。
所以你不能只用一个视角。
当然,如果你不做研究而纯粹靠想象,那么事情就会朝向一个相当诡异的方向发展,这也是我们常见的「傻逼产品经理三件套:直觉、经验、品味,以及一个 DLC:自我感动」,I believe you already know that。
研究方法是解剖信息空间的具体工具
在用户研究领域,有成百上千种研究方法。观察法、访谈法、问卷法、卡片分类、启发式评估、可用性测试、情境调查、田野研究……这个列表可以一直列下去。
假如现在你要研究一个软件,你想知道人们用起来顺不顺手,卡在哪里,感受如何。你手头有有限的时间和资源,不能把每种方法都用一遍。你需要做一些平衡,用最少的资源,获得尽可能多的有用信息。
你会怎么选?
最便宜的方法总是最先被考虑。它们不需要昂贵的设备,不需要等产品上线攒日志,也不需要把用户从他们熟悉的地方拽到实验室里。你可能会想,既然是研究软件,不如直接让用户上手用,看看他们怎么操作。所以你选了观察法,再配合出声思考,让他们一边用一边把心里想的说出来。这样你既能看到他们做了什么,也能听到他们在想什么。
你可能会犹豫:要不要在实验过程中提问?如果提问,那就变成了情境访谈,可以在用户操作的时候追问「你为什么点这里」。但你也担心,提问会不会打断用户的心流?会不会无意间给他们提示,反而帮他们解决了问题?权衡之后,你决定先不做情境访谈,保持观察的纯净,只让他们自然地说。至于那些「当时在想什么」的问题,可以留到任务结束后再问。
你可能会想,要不要亲自去用户的办公室看看他们到底是怎么用这个软件的,但又觉得不对劲,这又不是 Nintendo Switch 和 Nex Playground 这种合家欢的产品,使用场景如此单一以至于根本不需要下这个血本。
光看行为还不够,你还想知道用户内心当中到底对这款软件蛮不满意,他们到底觉得难不难、累不累、有没有信心。于是你从武器库里翻出两套标准化问卷,做完任务之后发给他们填,几分钟就能收完。它们不能告诉你具体哪里出了问题,但能告诉你用户具体的主观感受。
现在你有了行为数据和主观数据。但你还想从另一个角度看看这个软件,用户看腻了,不如来看软件本身吧。你找来几位懂 UX 的人,请他们沿着 Happy Path 走一遍,看看到底哪里做的不够,或者引入了反范式,让用户感到迷茫困惑和痛苦。专家能够从更高级的视角理解用户的心智,判断每一步的认知负荷,预测哪些步骤可能失败。这个过程不是用户在做,是专家在替用户想。你也请他们对着软件一条一条过尼尔森的十条启发式原则,看看哪些原则被违反了,哪些本该有的东西不存在。
数据的整合是对信息的设计
你拿到了一大堆统计数据,做了各式各样的分析,现在我们得到了好多好多的结果,但是怎样把它串成一篇报告则是另外一门学问。如果我们只是简单的把不同的结果堆叠、罗列,那么读者的思绪就会跳来跳去,这会让人感到疲劳,不知道该把注意力放在哪里,觉得莫名其妙。这和英文考试里面的段落排序题很像,单独的句子再漂亮,顺序错了也是一篇烂文章。
我们要准确的让前一句引出后一句,前一段引出下一段,整个论述脉络清楚,并且最后能够收束到结论上,这时我们就要看看学术写作的基本范式了。在学术写作中,你有一个核心问题要回答,为了回答这个问题,需要回答几个子问题,每个问题都需要数据支撑。这一个个证据串联成一个完整的论证链条,最后收束成结论。
在回答单个实验的具体问题时,你会发现好多组数据都会对答案有所贡献。比如现在你手头有四堆东西:用户的行为数据(他们做了什么)、用户的主观数据(他们感受到了什么)、专家的认知走查(他们的认知过程为何)、专家的启发式评估(构成这些认知的底层要素的优劣)。
它们有的时候彼此协同,有的时候互相冲突,如果想要让它们变成一个和谐而圆融的整体,我们就要对整个研究的架构作出整体的规划。
你先看了看来自真实用户的数据:
一类来自问卷。用户做完任务之后填的那些量表,告诉你他们觉得这软件难不难、累不累、有没有信心。这是用户对自己体验的评价,我们叫它主观数据。
一类来自观察。用户实际点了哪里、拖了什么、卡了多久、错了几次,这些都被记了下来。这是他们真实做过的事,我们叫它行为数据。
你注意到,问卷是主观感受,是行为体验的后果,二者有一个明确的逻辑关系。某个地方用户反复出错,事后打分也不高。另一个地方操作很顺,用户也觉得轻松。但如果只看这两类数据,你只能知道某种行为模式和某种主观评价之间有关联,却说不清这个关联背后的机制是什么。因为用户操作时的想法,他们怎么理解这个界面,他们以为自己在做什么,他们在哪个地方感到困惑,这些都没有被记录下来。因为很多时候用户自己也说不明白自己是怎么想的,除非你住在用户的脑子里,或者直接把电极插进去,否则这几乎就是不可知的数据。
这一层是认知过程,它需要用别的方法来捕捉。
PURE 方法,请几位专家(通常是三位),沿着用户的操作路径走一遍,模拟用户在每个步骤需要理解什么、推断什么、记住什么。和之前直接观察用户不同,现在我们来推演用户的认知过程。专家受过训练,知道哪些信息是必要的、哪些是缺失的、哪些地方用户会被卡住。他们可以判断每个步骤的认知负荷是高还是低,以及哪些步骤可能让用户感到困惑甚至放弃。
专家对用户的心智模型、认知过程进行评估,而这些决定了用户用一款软件的主观体验是开心的还是不愉快的,这是一个明确的逻辑关系。这些认知负荷的判断,和你之前收集的行为数据、问卷数据放在一起,会发现它们可以被很自然的接在一起。认知过程驱动了用户的主观感受。用户觉得一个步骤难,是因为那个步骤的认知负荷太高。用户觉得困惑,是因为界面没有提供足够的信息让他们理解当前的状态。换句话说,认知负荷的高低直接形塑了用户的主观感受。
现在还有一个问题。是什么决定了认知负荷的高低?或者说,是什么决定了心智模型呢?
这就需要另一类分析。还是这些专家,但他们直接对软件本身的特质进行审查。用户体验的诸多要素在启发式分析当中被阐述的很明确,是这些要素共同支撑了用户的心智模型。他们对照用户体验设计的基本原则,比如反馈是否及时、用语是否清晰、操作是否一致、出错时有没有帮助,来判断这个软件的设计在多大程度上符合这些原则。这些原则在学术领域通常被称为启发式,也就是构成良好用户体验的基本要素。
启发式分析得出的结论,落在认知过程的前面。一个软件如果在反馈、一致性、容错这些基本要素上有缺陷,这些缺陷就会直接转化为用户的认知负荷。用户需要自己去补足缺失的信息,去猜这个图标是什么意思,去想刚才的操作为什么没反应。这些额外的思考成本,就是认知负荷的来源。
至此,一个通顺的结果阐释逻辑徐徐展开,完整的逻辑链条是这样的。
软件的基本设计要素,也就是启发式评估看到的那些东西,决定了用户在操作过程中需要承受多少认知负荷,也就是认知走查判断的那些东西。认知负荷的高低直接形塑了用户的主观感受,也就是问卷测量的那些东西。而这种感受最终表现在用户的行为上,也就是观察记录到的那些东西。
这四类数据各自落在链条的不同位置上,组合成了一个逻辑严密的系统。把它们按照这个逻辑排好,你就会发现它们开始互相解释。设计要素的缺陷解释了为什么某些步骤认知负荷高,认知负荷高解释了为什么用户觉得难用,觉得难用解释了为什么他们在那里反复犯错。反过来,你也可以从行为倒推回去。如果看到用户在某个步骤反复出错,可以往前看是不是感受层面出了问题,再往前看是不是认知负荷太高,最终落在设计要素的哪个细节上。
当然,研究者对于阐释框架有裁定权。我超讨厌模板,这里的分析过程也不是为了给你一个模板,这当中的所有元素都可以根据你的研究方法抽换,只要最后能够组成一个完整的叙事脉络就好。这就像在玩七巧板,张三能拼成一个船,李四能拼成一朵花,王二麻拼了个太阳出来。这件事情没有对错之分,只是看待同一个事物的视角不同。
比如,可以认为认知过程应该摆在行为和评分之间:专家对认知负荷的判断,填补了行为和感受之间的空白。行为是外部可见的,感受是事后回溯的,而认知过程发生在两者之间,包括用户操作的时候在想什么、猜什么、困惑什么,这些东西不会被直接记录,但它们是连接行为和感受的桥梁。
这是我个人的观点,只要你的逻辑没有破洞,怎么解释,用什么顺序解释完全是你的自由,一切为问题的解决服务,为一个好的故事服务。
实际解决一个问题
现在你手里有四堆数据。你以为可以开始写报告了。但当你把它们摆在一起,你发现它们在互相矛盾,这个时候又该怎么办?这是我最近遇到的一个真实的困惑。
前些日子,我做了一个用户体验研究,研究对象是 Jamovi,一个开源的统计软件。你可以理解成一个免费的、长得有点像 SPSS 但更现代的统计分析工具。
这类软件有一个特殊的用户群体:他们懂统计,但未必懂软件。一个心理学研究生可能知道 ANOVA 是什么,但第一次打开 Jamovi 的时候,他需要花时间摸索「这个按钮在哪儿」「变量怎么拖进去」。这是研究 Jamovi 的一个切入点。
另外,开源软件还有一个特点:它的设计者往往是统计学家或者程序员,不一定是 UX 设计师。所以它可能会有一些「能用但不顺手」的地方。Jamovi 算做得不错的,但还是有值得挖的问题。
在研究中我发现了一系列不太好解释的矛盾:
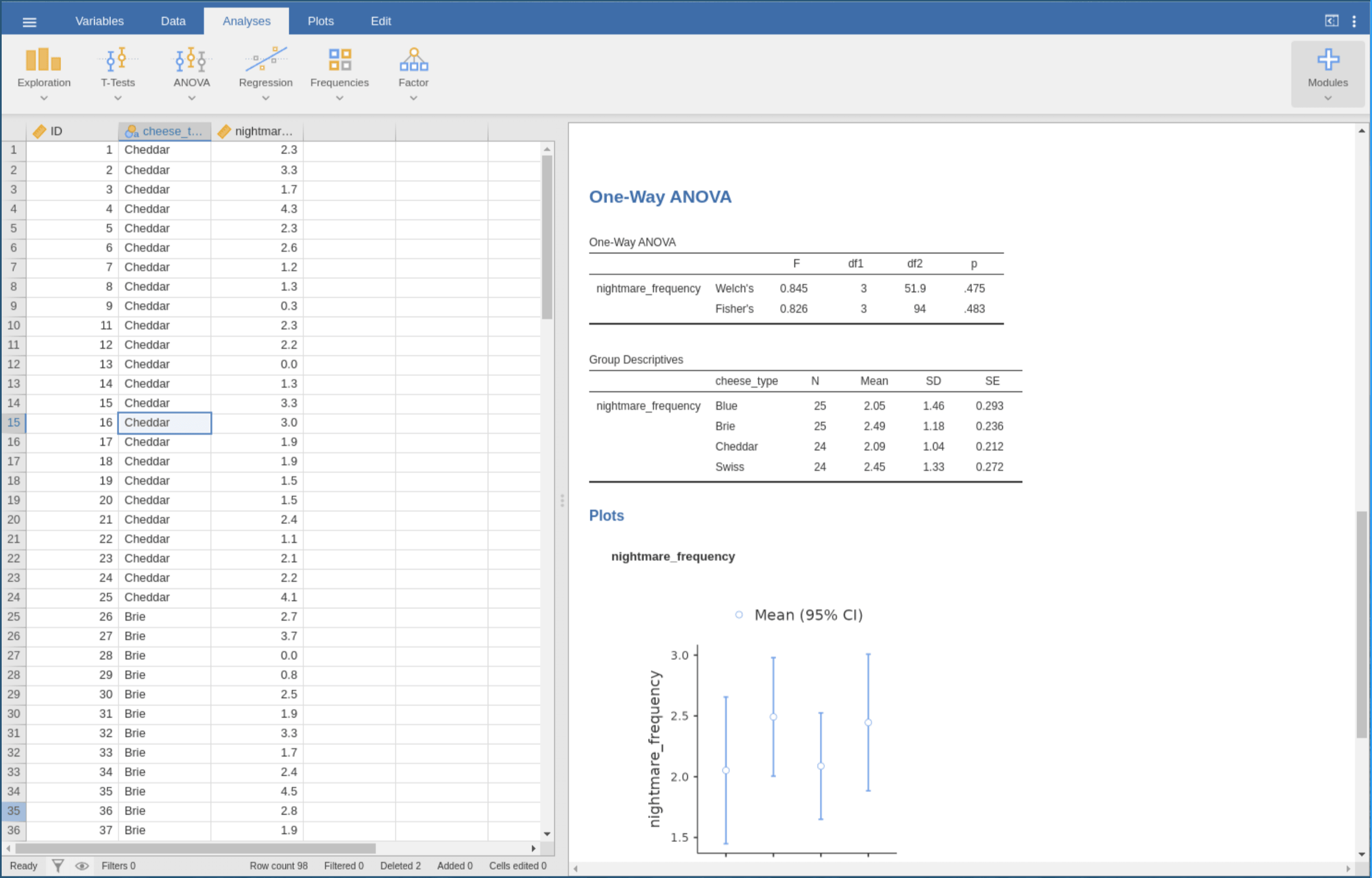
第一轮研究中,六个人用 Jamovi 做 ANOVA,我录了屏,记了他们的操作,做完之后发了问卷。问卷收上来一看,分数都挺好的。用户觉得这个软件不难用,任务负荷也不高。但回头看录像,我发现他们的错误率很高。有人拖拽同一个变量拖了五六次都拖不进去,有人试了几次之后干脆放弃任务,还有人用错了变量但自己没意识到,把分析结果复制粘贴回数据区,当作结论交差。这是主观体验和客观表现对不上。
在第二轮研究中,我请了三位 UX 专业的专家,用两种方法分析同一个软件。一种是 PURE 认知走查,让专家模拟用户的认知过程,给每个操作步骤的难度打分。另一种是启发式评估,让专家对照尼尔森的十条原则,给软件的设计质量打分。
结果出来之后,新的矛盾出现了。
PURE 评估显示,大多数步骤都是 1 分,也就是用户能轻松完成。只有一个步骤得了 3 分,也就是用户可能失败或放弃,即识别数据类型的错误。这个步骤没有具体的操作,是一个纯认知评估:用户需要自己发现「这个变量的类型是文本,应该改成数字」。

但回头看第一轮的行为数据,错误最多的地方并非那个 3 分的步骤!竟然能是一个 1 分的步骤!这个步骤是「把变量拖到分析框里」,它贡献了 29 次错误。
如果你单独把两个实验的任务对到一起,就会发现整个数据结构都是矛盾难以解读的。但如果我们把手头的所有数据摊开,试着用四层结构把它们排了一下。行为层来自录像,主观感受层来自问卷,认知层来自 PURE 评估,体验要素来自启发式评估。
先看体验要素。启发式评估显示,「诊断与恢复」和「帮助文档」这两项得分最高,意思是系统在用户出错的时候几乎不给帮助。你拖错了,它就闪一下图标,没有解释。
这个设计缺陷直接解释了认知层的问题。PURE 评估里那个 3 分的步骤,识别数据类型错误,为什么难?因为这个推理任务需要用户自己完成,系统不给任何提示。
认知层的失败是不可见的。事件编码里不会有一条叫「用户未识别数据类型」,因为它发生在脑子里。但这个不可见的失败会在行为层表现出来。用户不知道为什么拖不进去,只能一遍遍试,于是就有了那 29 次拖拽错误。
主观感受层为什么平静?因为用户不知道自己有认知任务没完成。他们不觉得难,是因为他们根本没意识到自己错过了什么。
现在再回头看那两个矛盾。
第一个矛盾,主观低分但行为高错,是因为认知层的失败不可见。用户不觉得难,但行为骗不了人。
第二个矛盾,专家预测的难点和用户实际的错误点对不上,是因为那个 3 分的步骤是认知前提,它没有直接的操作对应,所以行为数据里看不到它的失败。但这个前提没完成,导致后面所有依赖它的操作反复出错。所以错误集中在那个 1 分的步骤上,是因为它依赖前面那个 3 分的步骤。
两个矛盾,在这个四层结构里走一遍,就都能解释了。
理解信息设计的思维模式
我见过太多这样的情况。一个有用的分析工具被提炼出来,然后被当作公式套用。下一批研究者拿到自己的数据,机械地往层里填,填完之后报告看起来像模像样,但那个框架原本要解决的困惑、原本要揭示的关系,被填表的过程稀释掉了。框架成了装饰,不再是思维的工具。
这不是框架本身的问题,是使用方式的问题。
那个四层模型是从研究设计和数据当中自然生长出来的。第一轮研究有两类数据:用户的主观评分和客观行为记录。它们打架,主观说「不难」,行为说「错了很多」。第二轮研究又有两类数据:专家的认知走查和启发式评估。它们也打架,专家预测最难的一步,用户根本没在那里出错;用户错得最多的一步,专家说很简单。
四堆数据,两两打架。我需要一个方式让它们停止打架,开始对话。
于是我开始想这些数据到底在说什么。它们在说不同层面的事情。主观评分说的是用户感受到什么,行为记录说的是用户做了什么,认知走查说的是用户需要理解什么,启发式评估说的是软件提供了什么。这四个层面不是平行的。如果把它们按因果顺序排起来,就出现了一个结构。
软件的设计要素来自启发式评估,它决定了用户在操作中需要承受的认知负荷,也就是认知走查测量的东西。认知负荷的高低形塑了用户的主观感受,也就是问卷里呈现的那些评分。主观感受是用户连续行为导致的综合体验结果,行为也就是录像里记录的那些操作。
这个结构帮我解释了所有矛盾。那个最难被用户识别的步骤,也就是识别数据类型错误,是一个认知任务,它没有直接的操作,所以行为数据里看不到它的失败。但这个认知任务没完成,导致后面所有依赖它的操作反复出错。所以错误集中在那个看似简单的拖拽步骤上。用户不觉得难,是因为他们根本没意识到自己错过了什么。
四层模型不是发明,是发现。它是我手里那堆数据能形成的最简洁、最自洽的解释。
如果我把这个框架当作模板递给别人,说以后做研究就套这四层,那我就背叛了自己。因为下一次的研究可能没有行为数据,可能用的是田野调查而不是访谈,可能研究的不是软件,变成了在线服务。
整个框架当中的一切都是可以变的。层数可以变,每一层的内容可以换。唯一值的保留的是阐释问题的逻辑,也就是不同层面的数据之间存在因果或解释关系。
所以我想分享的并非所谓的「万能的报告模板」,模板在大部分情况下都是某种有毒的东西。我想向你展示一个完整的思考过程,这个思考过程可以帮你理解更广泛的问题。当你手里有打架的数据时,你可以试着问自己,它们在哪个层面说话。哪些层面是原因,哪些是结果。如果你能画出这样一张因果图,你就有了自己的框架。
研究方法的核心要义,不是手里握着一大堆花里胡哨的模板,是能在需要的时候,为自己手头的问题打造一个逻辑通顺的论证框架。
我今天带来的这个四层模型,只是我造的那个。我希望你能理解造它的过程,获得创造它的能力。
我知道这是很硬的一篇文章,非常感谢你能读到这里还能保持理智。在此仅能献上至高的祝福,祝你大便通畅,不沾马桶。
DIKW體系是關於數據(Data)、資訊(Information)、知識(Knowledge)及智慧(Wisdom)的體系,當中每一層都比下一層增加了某些特質。資料層最為基本,資訊層加入內容,知識層加入「如何去使用」,而智慧層加入「什麼時候才用」。如此,DIKW體系是一個讓我們了解分析、重要性及概念工作上的極限的體系。DIKW體系常用於資訊科學及知識管理。摘录自 Wikipedia。 ↩︎


Loading comments...