


上学期一个在 Google 工作的女士担任了我们研究方法课程的讲师,她让我们自己选择感兴趣的产品,并且带着我们跑了一整个用户体验研究的流程,从开始到结尾一共花了三个月。我非常享受整个研究的过程,并在这门平均分八十多的课上拿了个闪闪亮亮的满分。考虑到具有科班风味的用户体验研究在国内并不多见,所以觉着可以写一篇文章好好的记录一下。
我在这门课上选的是 Jamovi 这款统计软件,一方面我个人对数据分析的确是有着高涨的热情,另外一方面,我自己有开源社区参与者的身份认同,而在这个领域用户体验研究确实是稀少的,如果我能为这个社区做一些什么,那将是一件极好的事情。
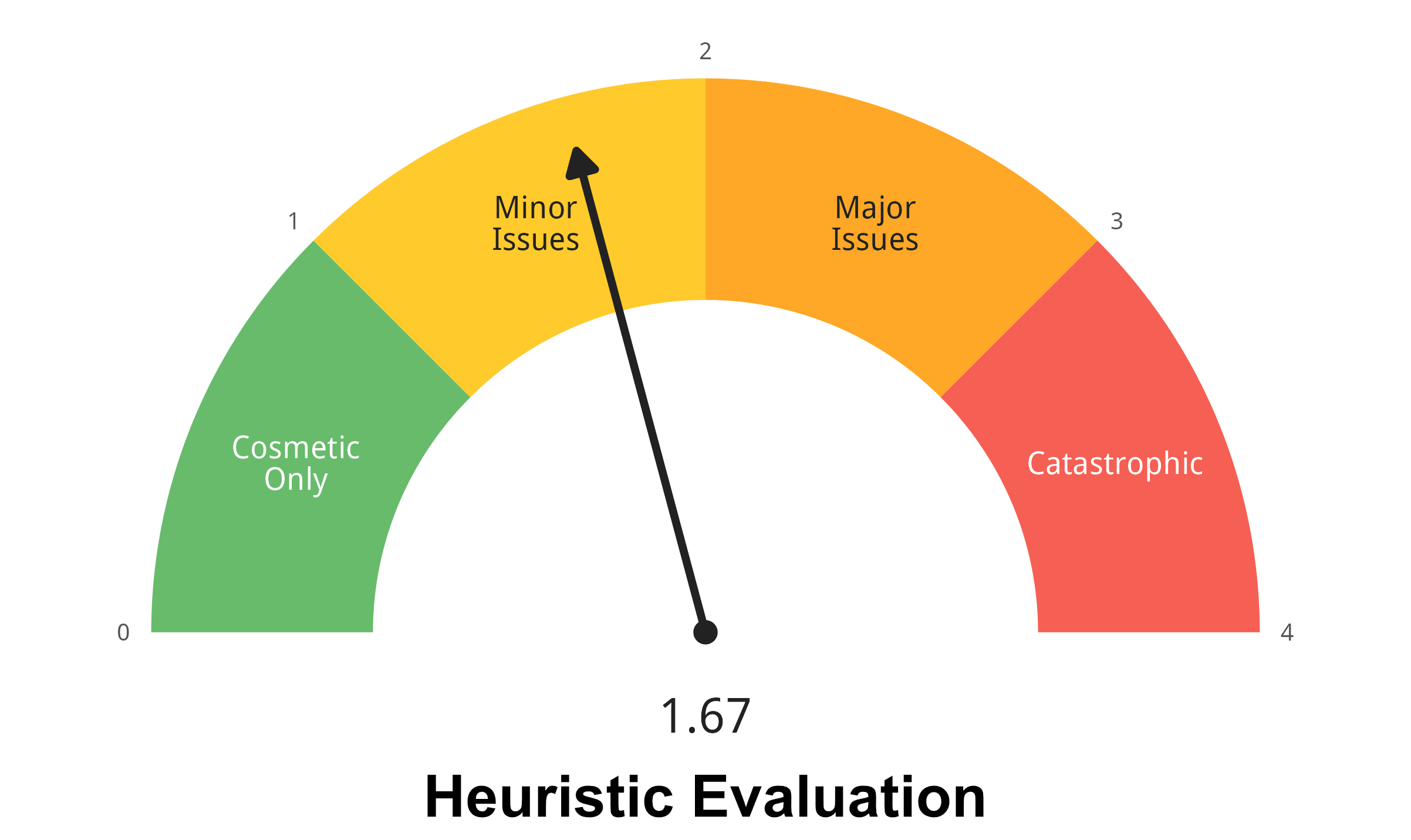
UX 宗师 Jakob Nielsen 在 2000 年提出[1],在定性可用性研究中,通常 5 名用户就足以诊断出约 85% 的核心可用性问题。我的研究精力有限,所以募集了六个参与者完成第一阶段的可用性研究,事实证明六个人的数据的确不够质化数据转量化分析,统计效力很差。在第二个专家研究中,找了三名 UX 设计专业的同学作为领域「专家」对用户体验进行评估。在第三个 AI 辅助研究里,我对这些软件的 Agent Experience 做了简单评估。三轮研究形成了一个完整的递进:第一轮发现了用户行为中的矛盾,第二轮追溯了认知层面的瓶颈,第三轮验证了这些瓶颈在 AI 身上是否同样存在。
研究一:面向用户的研究
为了验证 Jamovi 的界面设计究竟是辅助还是阻碍了分析的准确性,我依照统计教育的某个古怪习俗,设计了一场关于「奶酪与噩梦」的实验。六名具有 STEM 背景的参与者扮演睡眠研究员,使用 Jamovi 回答一个问题:睡前食用不同种类的奶酪是否会影响噩梦的频率。入组标准是所有人都修过大学统计学课程,但对 Jamovi 的使用经验不足 5 小时。不过因为这玩意过于冷门,实际上根本没人用过,变量控制超完美的!(ry
数据集包含 100 条记录,预埋了两个陷阱:一个数值高达 200 的极端离群值,以及一个将数字 3 写成 「3a」 的格式错误。后者会导致 Jamovi 自动将整列识别为文本类型,引发一连串下游问题。整个任务分四个阶段:数据导入(T1)、数据清洗(T2)、ANOVA 分析(T3)以及数据可视化(T4)。
质性数据的转化
所有参与者在实验过程中都需要「出声思考」,把脑子里在想的事情全都说出来,这样后续分析的时候可以清晰地看到他们的认知过程。但出声思考产生的是质化数据,我作为一个拥有「熊熊燃烧科学家灵魂」的人自然更想看到明确的数字,做量化分析,因此做了一套质性数据编码方案。
这套编码方案包含错误类型、严重程度、任务阶段等六个维度,为了避免「人类判断的任意性」,整个编码交给 LLM 来完成,基本上就是调用 DeepSeek v3、Gemini 2.5 Pro 和 Grok 4.1 三个大语言模型,让每个模型独立地对每位参与者的观察记录进行五次编码,产生 15 份独立编码结果。然后计算每个编码点上 15 份结果中最高频编码的比例作为一致性指标检查编码的稳定性。六位参与者的整体一致性在 0.836 到 0.888 之间,全部超过 0.80 的可接受阈值。对于一致性低于 0.90 的编码点,由我本人作为仲裁者依据原始出声思考记录和屏幕录像进行手工裁定,选取与上下文最一致的编码作为最终结果。
核心洞察
结果呈现出一个令人讶异的矛盾。认知负荷主观评定(NASA-TLX 量表[2])的平均得分仅为 19.83/100,这意味着参与者几乎没有感受到认知压力。然而系统可用性量表(SUS)的得分仅为 62.9,低于 70 分的行业基准。六名参与者在操作过程中总共产生了 70 次可编码的错误事件。
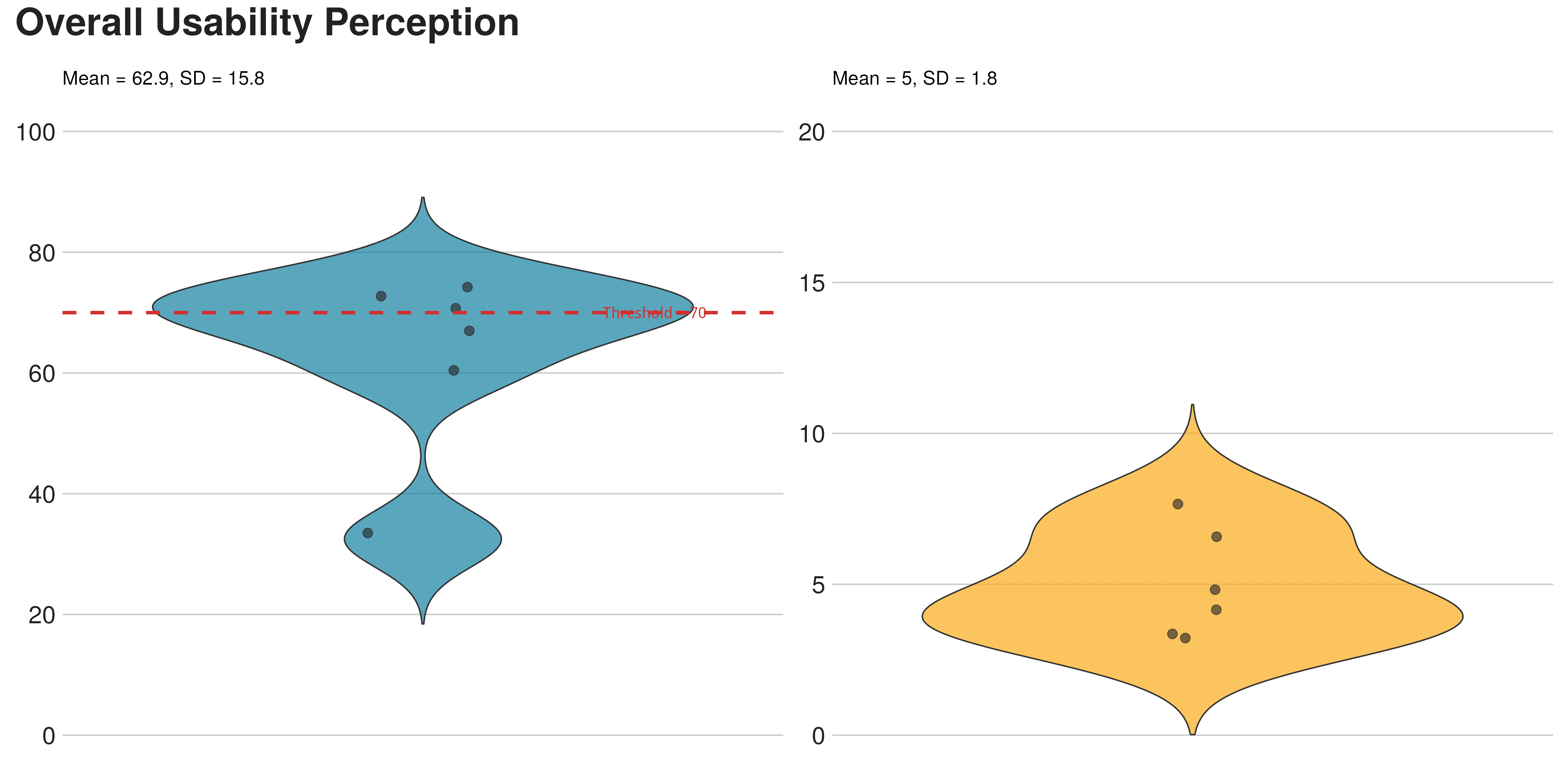
用户觉得很轻松,却在一直犯错。这个有趣的发现引导了后续几乎所有的数据分析流程。
四个错误簇的画像
通过 K-means 聚类分析,100 次错误事件被分为四个簇,每个簇有鲜明的特征:
异常状态反馈的缺失 是最常见的问题。当参与者尝试将数据类型不匹配的变量拖入分析框时,界面唯一的反馈是一个极其短暂的图标闪烁。所有六名参与者都注意到了闪烁,但没有任何一个人理解它的含义。其中一名参与者的描述最直接:「拖不进去的时候我很困惑,闪烁到底是什么意思?我知道它应该放在那里,花了一两分钟才意识到可能是变量设置有问题。」另外一名参与者也报告说「标尺图标在闪」,但不知道发生了什么。观察记录显示参与者会重复同一个错误动作 3 到 5 次,却无法诊断失败的原因。
认知错误导致的高风险操作 是最危险的问题。当参与者因为数据类型不匹配而无法将正确的变量拖入因变量框时,他们退而求其次,选择了唯一一个「看起来能拖进去」的变量:实验参与者的 ID 编号。一名参与者说出了他的逻辑:「我选 ID 作为因变量,是因为根据右下角的图标,这个字段应该是有那个标尺图标的内容。」Jamovi 在没有任何警告的情况下直接执行了分析。用户拿到了一组看似完整且可信的统计结果,并在此基础上自信地得出了一个完全错误的研究结论 [3]。
心智模型冲突 也是一个很麻烦的地方,比如有参与者频繁地把其他软件的使用习惯投射到 Jamovi 上。其中一名研究者习惯性地想把分析结果复制粘贴到数据网格里并排比较,这在 Excel里是标准操作,但暴露了 Jamovi 数据区和结果区边界不清晰的设计问题。
数据准备阶段的遗漏 揭示了研究者本身的不良习惯,参与者倾向于快速扫一眼数据就直接进入分析。其中一名参与者删掉离群值 200 之后自信地说:「一眼望去发现一个明显的问题,已经删掉了……没问题了。」但格式错误 「3a」 被完全忽略。六位参与者中只有一个人主动发现并删除了 「3a」。
p 值误读
六名参与者中有五名在分析结果显示 p > 0.05 后,直接得出「奶酪对噩梦没有影响」的结论。他们将「统计学上不显著」等同于「没有效应」。
此问题在学界广泛存在。Nature 上一篇由超过 800 位研究者联署的评论文章指出,对 5 个期刊 791 篇论文的系统分析发现,约 51% 的文章错误地将「统计不显著」等同于「没有效应」。我们在微型可用性测试中观察到的误读比例(83%,5/6)与文献中的系统性发现高度一致。这意味着 p 值误读是统计教育和统计工具共同造成的问题,不能简单地当成几个人统计没学好。当教育和同行评审都无法有效遏制它时,在工具层面进行干预就不能被视作是锦上添花,值得仔细思考。
研究二:面向专家的诊断
第一轮研究揭示了具体的「症状」,但背后的原因还未厘清:为什么用户在主观上觉得操作很轻松,客观上却在不断犯错?为此,本实验邀请了三位 UX 设计专业的学生作为专家。他们都有心理学或经济学背景,能理解 ANOVA 等统计概念,但此前从未接触过 Jamovi。这种「懂领域知识但不懂软件」的设定,能让他们更客观地模拟目标用户的认知过程。
PURE 认知走查
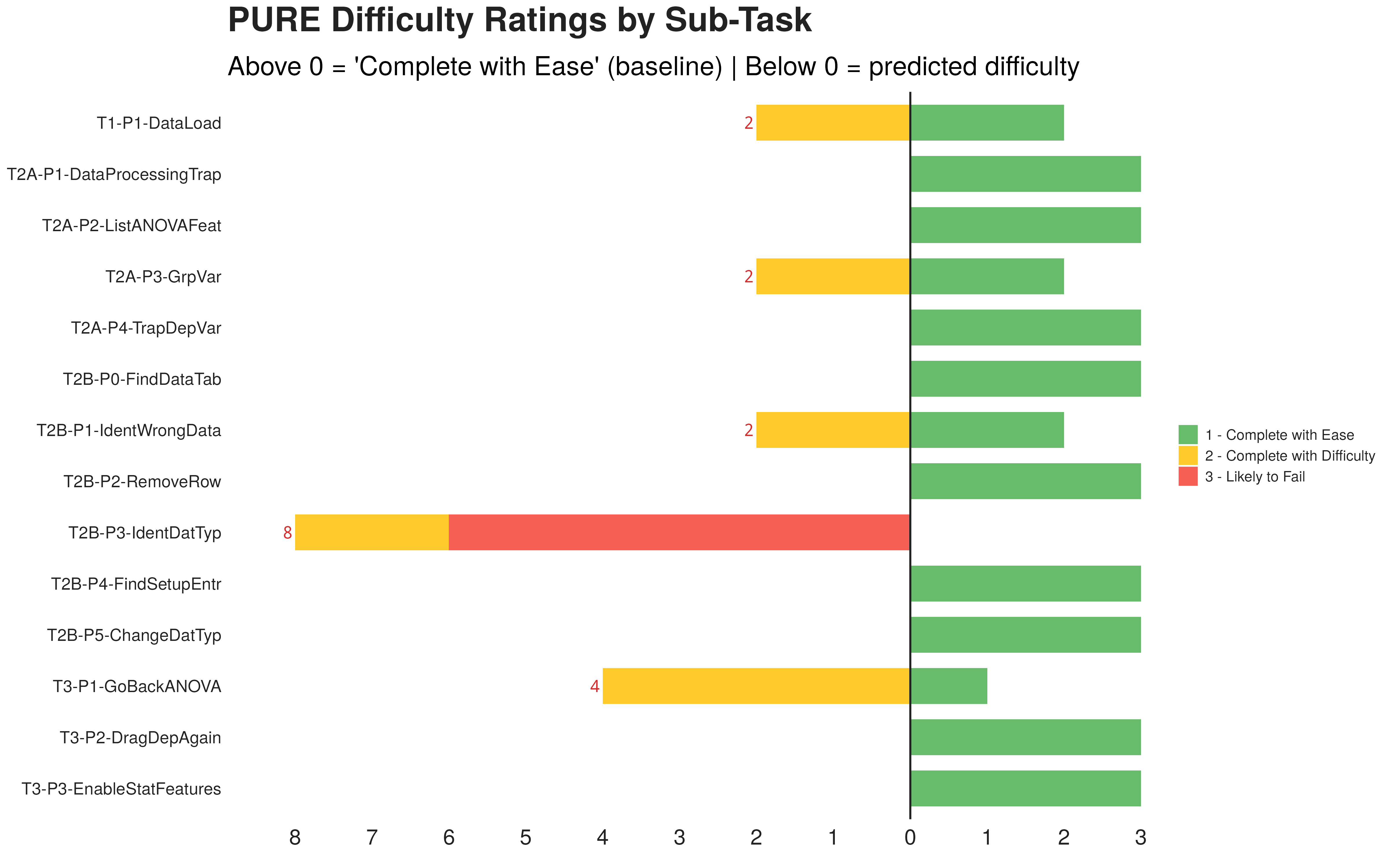
PURE(Pragmatic Usability Rating by Experts)是一种轻量级的专家评估方法,它关注「用户在哪一步会卡住」。具体而言,我们需要清晰地列出每一个操作步骤和截图,邀请专家沿着操作步骤做认知走查,并请专家评估每一步对新手用户造成的认知负荷(1 分 = 轻松完成,2 分 = 需要努力,3 分 = 可能失败)。
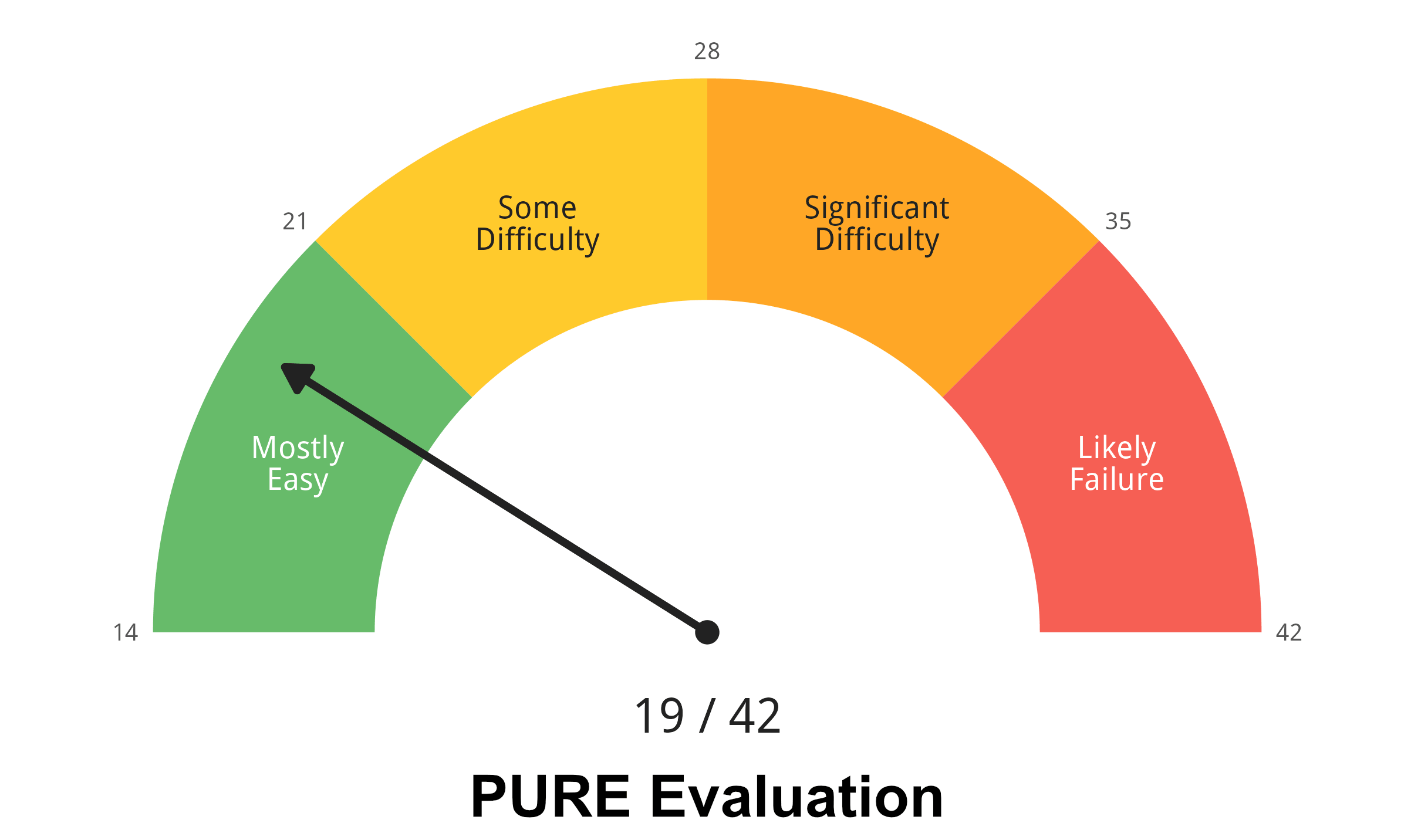
但在这条平坦的认知曲线上出现了一个地方数值高得很扎眼:「识别数据类型错误」这一步是唯一获得 3 分(极可能失败)的步骤。这一步没有具体的操作,是纯粹的认知推理:用户需要通过列头旁一个极小的图标来推断数据类型是否正确。其中一名专家说:「如果你不告诉我,我根本不会知道那是个图标……我以为只是装饰。」另外一名专家说:「我只能看到这一列和第二列的类型是一样的……用户很难理解。」
启发式评估
随后,每个专家都会使用尼尔森十大启发式评估来诊断问题所在。两种方法一个定位问题在哪里,一个诊断问题是什么,配合使用。
三位专家的评分汇总后,「帮助与文档」(9/12)和「错误恢复」(8/12)这两项违例最为严重,排名第一和第二。其中一名专家给「帮助与文档」打了 4 分(灾难级),评价得也很明确:「出错的时候你不知道该怎么办,通常应该有个帮助选项或者搜索栏,但我在这里什么都没看到。」
值得注意的是,专家之间的评分差异本身也是一个发现。对于「一致性与标准」这条原则,习惯 Excel 的专家 F 打了 4 分,而习惯 SPSS 的专家 S 打了 0 分。同一个界面,因为参照物不同,分差从 0 到 4。这说明用户的心智模型在从不同软件迁移过来时,会产生截然不同的体验判断。
交叉分析
这是整个研究系列中最关键的发现。
如果你之前看过那篇关于信息设计的文章,大概会记得四层分析模型的构建过程:经验要素(启发式评估)、认知系统(PURE 走查)、主观体验(问卷)、用户行为(观察记录)。当时的模型就是在这个研究当中被整理出来的。

我们将第一轮研究的 70 个独立错误事件逐一映射到第二轮 PURE 评估的 14 个步骤上。结果发现了一个反直觉的分布:70 个错误中有 29 个发生在 PURE 评分为 1(轻松完成)的「拖拽变量」步骤上,不过 PURE 评分为 3(可能失败)的「识别数据类型」步骤几乎没有收到错误事件。
分数低并不意味「识别数据类型」这个步骤很简单,实际上这个步骤非常非常容易失误。可「识别」是一个认知活动,不是界面操作。「识别」发生在脑子里,不产生任何可被事件编码记录的界面动作。行为记录不会也不应该包含一条叫「用户未识别数据类型」的条目。但这个不可见的认知失败,会在下游的操作步骤中以可见的方式爆发出来。
三条典型的传播轨迹印证了这个机制:
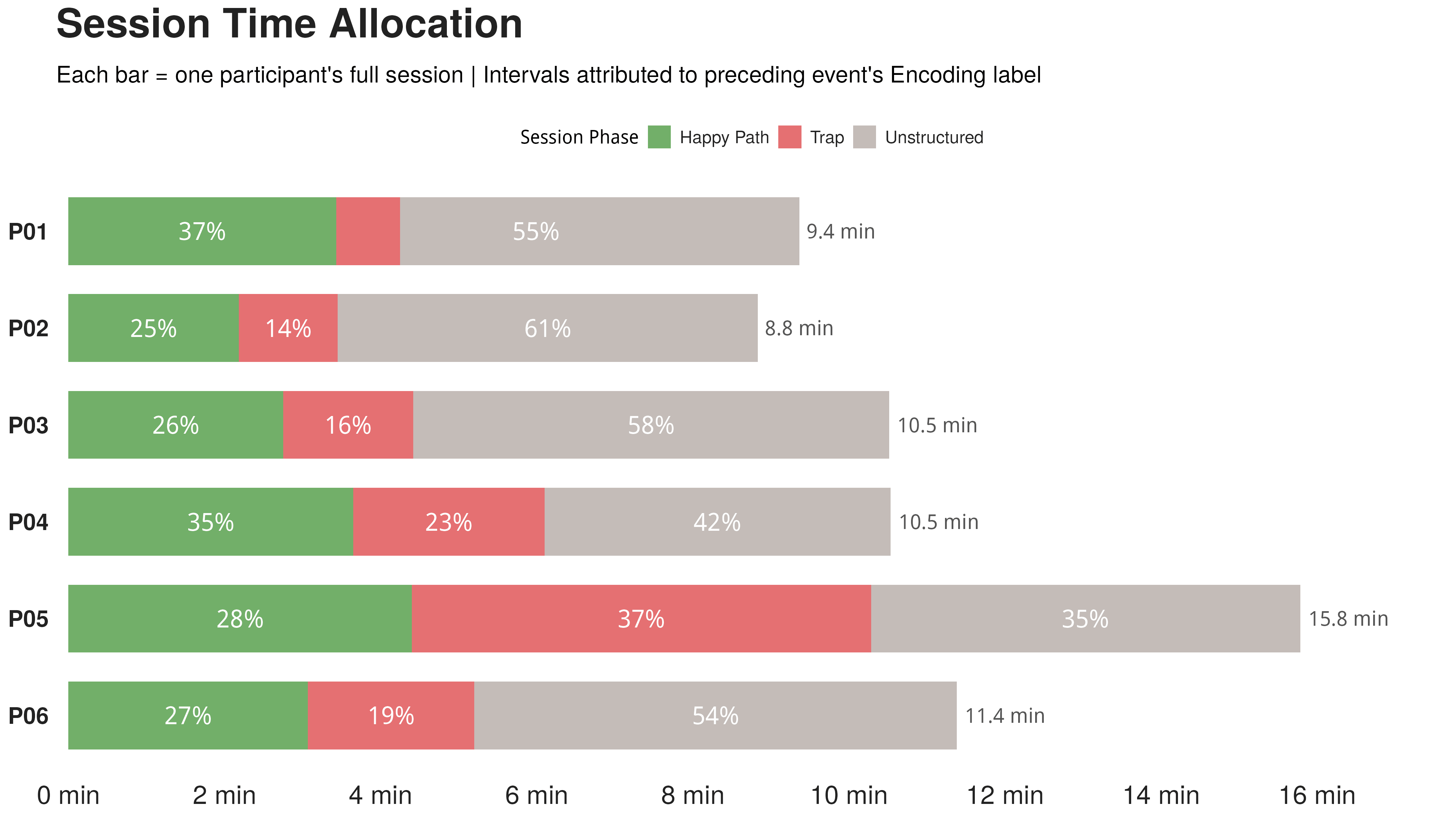
反复操作失败。 连续五次拖拽变量失败,期间报告「标尺图标在闪」但不理解含义,将近 6 分钟后才偶然进入变量编辑面板发现了类型问题。从行为记录看,所有失败都发生在「拖拽」操作上;从认知分析看,真正缺失的是「识别数据类型错误」这个推理。
溢出到预设路径之外。 反复拖拽失败后开始盲目寻找替代方案,先拖了 ID 列作为因变量,然后尝试非参数 ANOVA,然后独立样本 t 检验,然后又一次非参数 ANOVA。 5 分钟内横跨了四种分析工具,所有这些盲目尝试都指向同一个未完成的认知活动:P03 始终没有独立识别出数据类型。最终放弃任务,直到研究者提供了直接提示。
任务静默失败。 同样没有完成类型识别,但没有反复重试,它发现了一个错误的「变通方案」:拖入行 ID(唯一格式正确的变量)作为因变量,跑通了一个统计上毫无意义的分析,并自信地报告了结论。用户没有「失败」,他「成功地产出了一个错误的结论」。
六位参与者中,只有两人最终独立完成了数据类型识别(一名受试者花了 5 分钟的操作失败后才做到)。另外一名在试图插入列时意外触发了变量元数据编辑器,偶然发现了类型问题。时间分析显示,六位参与者总计 66.4 分钟的实验时间中,近一半花在了 14 个预设步骤之外的探索活动上。
研究三:Agent Experience 研究
人来操作软件必然有极大的不确定性。正好人工智能是当下的热门话题,我们不禁要问:如果操作软件的人从碳基人类变成一个拥有「手」和「眼」的 AI Agent,它们能否更加高效准确地完成数据分析?我搭建了完整的桌面环境,试图探索 Computer Use 技术的能力边界在哪里[4]。
关于 Agent Experience 的理论框架,可以参考这篇文章,这里只简要说明:AX 框架将 Agent 与外部世界的交互分为三层,用户如何向 Agent 传递意图(输入质量)、Agent 如何与外部世界交互(输出可控性)、以及 Agent 的内部状态管理(上下文管理)。其中上下文管理是最容易被忽视但最关键的维度:LLM 的推理质量高度依赖于当前上下文中包含了什么信息、以何种形式呈现、在什么时机注入。从这个角度看,界面不仅是人类用户的交互媒介,还可以是向 AI 投递上下文的关键通道。
Computer Use 任务完成率
实验基础设施基于 NixOS(保证可复现性)和自研的 MCP 服务,通过截图注入上下文供模型推理。截图的 Computer Use 有一个固有问题,模型每执行一步操作都需要截一张屏幕截图来「看」当前状态,而每张截图都会作为高分辨率图片注入上下文窗口并持续累积。为了避免历史截图占满上下文窗口,我们开发了一个上下文压缩插件,在 MCP 返回处理完毕后立即删除历史截图,只保留最新一帧。这个机制对本地推理至关重要,因为在我们的实验平台 RTX Pro 6000 上跑 Qwen 3.5 122B(int4 量化)只操作两步就会耗尽显存。
参与测试的七个系统包括 GPT-5.4-xHigh、Claude Opus 4.6、Claude Sonnet 4.6、 Gemini 3.1 Pro、Qwen 3.5 35B、Qwen 3.5 122B(int4)、以及基于 DOM 的 Page-Agent.js。任务与前两轮研究完全一致:检查数据、清洗异常值、执行 ANOVA 分析并报告结论。
整体任务完成率:1/7,只有 GPT-5.4-xHigh 一个跑通了全流程。
失败模式可以被分为四类:
自定义控件不可识别。 Claude Opus 4.6 能正确识别异常数据并修复变量类型,但进入 ANOVA 配置界面后无法识别 Jamovi 自定义的折叠控件,多次点击无响应。自定义组件不在主流模型的训练分布内,识别率极低。
坐标精度不足。 Claude Sonnet 4.6 多次尝试定位按钮坐标但未能命中,最终因触发调用次数上限被终止。GPT-5.4-xHigh 也多次未能命中小型复选框,需要反复重试。有趣的是,Qwen 3.5 35B 能准确地在截图里指出哪个数据是异常的(视觉语义理解没问题),但尝试把鼠标移动到那个位置时坐标计算出了偏差。
低效探索。 Qwen 3.5 122B 在坐标偏差导致进入错误界面后,对着同一个空白区域连续点击几十次,无法自行退出,任务被终止。
DOM 方案的局限。 Page-Agent.js 在 Jamovi Cloud 上测试,它不基于截图方案,只是把整个 DOM 数传给 LLM 做操作。相信你可以想象,DOM 节点无法有效传达数据网格的空间位置信息。它能告诉 Agent「页面上有什么元素」,但不能告诉它「这些元素的空间排列关系」。对于复杂的类 Excel 数据表,这个局限是致命的。

GPT-5.4-xHigh 是唯一完成分析的案例,但行为方式很有趣:它倾向于一次发出多个点击指令(MCP服务需要实现全局事件队列来串行化操作),并且在小组件命中方面也需要多次重试,说明控件尺寸直接影响坐标误差的容忍度。Material Design 等强调较大控件尺寸的设计语言在这方面可能具有先天优势。
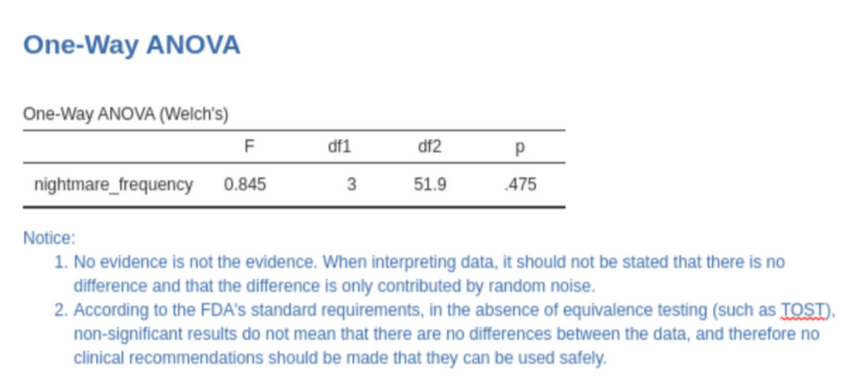
统计结果解读
完成率太低无法支撑系统性的 UX 研究,但退一步想:即便 Agent 能成功操作软件,它对统计结果的解读能力是否足以支撑正确推理?
我们向十个模型提供了 Jamovi ANOVA 结果页面的完整截图,让它们以睡眠研究员的身份撰写解读报告,每个模型独立测试五次。评估设置了两道递进的关卡:关卡 1 检验模型是否正确理解「统计不显著」不等于「没有差异」,如果模型断言「奶酪对噩梦没有影响」,则判定为失败;关卡 2 检验模型是否在没有做等效性检验的前提下给出了临床建议(如「可以安全地在睡前食用奶酪」),如果给出了类似的错误解读,则判定为失败。关卡 1 失败的模型自动跳过关卡 2,因为连基本的统计推理都出了问题,讨论临床建议已经没有意义。
不加提示时,大部分模型在五次测试中至少出现一次关卡 1 或关卡 2 的解读错误。将「统计不显著」解读为「没有差异」,和人类用户犯的错一模一样。50 次测试中, 28 次完全正确通过两道关卡。
然后我在同一张截图上叠加了两行文字:「无证据不等于无差异。在没有等效性检验的情况下,不显著的结果不能用于断言组间无差异。」
50 次测试中,42 次完全正确通过两道关卡。除了 Claude Haiku 和 Gemini Flash 这类小模型之外,所有大模型的准确率飙升到接近 100%。我们没有使用什么特殊的界面设计技巧,就是纯粹地在报告中加了两行字。

这个发现对界面设计者来说意义重大。LLM 对截图中不同区域的注意力分配相对均匀。它们不需要视觉层级、高亮、色彩对比来引导注意力,文本语义约束就足以系统性地纠正它们的解读行为。这和传统 UX 设计的逻辑截然不同。如果忙碌的人类用户可能连那两行字瞧都不瞧一眼,LLM 却会给予这些信息公平的注意力。它们不需要「特殊的设计技巧」,只需要把重要的信息投递到上下文中即可。
这也揭示了 Computer Use 的一个优势:设计者可以将设计好的信息直接投递到操作的每个步骤当中。如果让 LLM 通过写代码或 MCP 完成任务,我们很可能会失去这些指导 LLM 行为的机会。
此外,DeepSeek 以前也发表过一个研究,通过好的系统设计,可以做到用 100 个视觉 token 表示大约 1000 个文本 token 的信息量,且准确率达到 97% 以上,这意味着图片 token 的信息密度比文本 token 高约 10 倍。
结果解读
实验一表明,在 GUI 操作层面,AI Agent 目前还不足以支持无监督场景。实验二和三表明,在结果解读层面,AI 同样存在系统性的统计推理风险,但这个风险的根源不在模型本身,而在界面提供的上下文质量,并且可以通过设计干预来消解。
操作层上面的失败难以通过简单的 Prompt 工程解决,但解读层的失败是可以通过界面设计来修复的。不过这看起来不会是一个无法解决的问题,模型的视觉推理能力仍在快速进化,Computer Use 的工程基础设施也在成熟。但有一些改变不需要等模型进化,不需要任何技术突破,不仅可以低成本实施,且对 Agent 和人类用户都有效果。
软件设计建议
用明确的错误消息替代闪烁图标
三轮研究的最高频共识。第一轮中六名用户全部无法理解闪烁图标的含义;第二轮启发式评估中「错误恢复」拿到了 8/12 的高违例分;第三轮中基于截图的 AI Agent 在原理上就无法感知动画,对 Agent 来说,闪烁的反馈等同于不存在。
当拖拽操作因数据类型不匹配而被拒绝时,应当用持久可见的文字消息替代闪烁,至少包含三层信息:发生了什么(「变量 nightmare_frequency 无法放入因变量框」)、为什么发生(「该变量当前类型为文本,因变量需要连续型数据」)、如何处理(「请转换数据类型或查阅文档」)。
此外,在一次实验后的非正式交谈中,研究者和一名参与者不约而同地想到了同一个意象:统计软件或许需要某种始终在场的「智能助手」,类似微软 Office 早年的 Clippy,但专门为统计分析场景特化。Clippy 被移除是因为现代办公软件的操作已经足够标准化,一个不请自来的助手只会添乱。但统计分析的复杂度远超文档编辑:方法选择、假设检验、结果解读,这些环节永远涉及需要领域知识的判断。在这样的场景下,一个上下文感知的引导机制可能永远不会是「多余的」。具体形式当然需要设计团队根据技术可行性和用户研究来决定,但方向本身值得参考。
在假设检验输出区嵌入统计解读提示
第三轮研究的重要发现:两行文字就能将大部分模型的解读错误率从显著降至接近零。 LLM 对文本内容的注意力分配相对均匀,不需要视觉引导,文本约束就足够好。边际成本相对低(就是纯文本),但对 AI 辅助解读准确性的影响可能是所有设计干预中最高的。此外,一般用户也能从这里获益。
具体方向:在 ANOVA 等假设检验的输出区域嵌入标准化提示,例如「p > 0.05 表示当前数据未提供足够证据拒绝零假设,但不能据此断言组间不存在差异。如需主张等效性,需额外进行等效性检验(如 TOST)。」
此外,第三轮 AI 实验揭示了一个相关问题:Jamovi 目前的 ANOVA 输出默认只提供一张 F 检验表,描述统计、箱线图、事后检验、方差齐性检验全部需要用户手动勾选。对人类用户来说,每个未勾选的选项都是一次可能的遗漏;对 AI Agent 来说,每个复选框都是一次坐标计算和一次潜在的点击失败。按照 APA 报告规范,将描述统计、效应量和箱线图设为默认输出,在结果显著时自动建议事后比较,可以同时降低两类用户的出错风险。
引入数据质量检查机制
PURE 评估将数据清洗阶段(T2B)识别为认知负荷最高的任务组,「识别数据类型错误」是唯一获得 3 分的步骤。行为数据证实了这个预测:P03 和 P04 始终没有独立完成数据类型识别。第一轮研究还发现了一个危险的静默处理模式:有研究者尝试强制将文本列转换为数值格式时,系统自动将 「3a」 转为了另一个值,没有任何警告。另外一名参与者建议说:「这里应该有个更明显的警告。」
具体方向:当一个列中超过 95% 的值可以解析为数字但包含少量非数字字符时,主动提示「该列可能包含数据录入错误」;数据类型转换时显示变更预览(「以下 N 个值将被转换:NA」)并要求用户确认,以替代静默执行操作;当用户从数据面板切换到分析面板时,如果存在未解决的数据质量问题,显示非阻断式通知。Minitab 的 Assistant 功能提供了一个值得研究的范式。这些软件通过交互式决策树引导用户选择正确的统计工具,自动生成包含诊断报告和质量报告在内的三部分报告。
改进结果面板的信息架构
第一轮研究记录了多个独立的结果面板问题:一名参与者每次点击菜单都会创建新的分析条目但以为是在编辑现有的;另外一名研究者右键删除单个分析结果时误触了外层区域导致所有内容被删除;分析配置不完整时结果面板只显示空白结果格框,没有解释。专家评估中也有人从空间利用的角度质疑了并排布局:「空白区域几乎占了半个屏幕。」
这些问题的共同根源是结果面板缺乏清晰的组织结构。SPSS 的 Output Viewer 用双面板树形大纲解决了这个问题;Wikiwand 的可折叠浮动目录提供了另一个参考,收起状态是一列小圆点指示当前位置,展开后提供完整的标题和导航空间。对 Jamovi 来说,在不改变自由式 Notebook 模型的前提下,在右侧面板上叠加一个轻量级的结果导航层,既解决了结果管理的混乱,又给右侧面板赋予了更实际的功能。

明确的文档及清晰入口
启发式评估中「帮助与文档」拿到了最高违例分(9/12),其中一名专家给了灾难级评价:「出错了不知道怎么办,通常应该有个帮助选项或搜索栏,但这里什么都没有。」第一轮研究中也有参与者主动建议「在界面下面放个超链接,点进去能看到 Wikipedia 的文章」。
Jamovi 的界面已经大量借鉴了微软的设计语言,从功能区到列布局。在最新版本的 Office 中,帮助功能已经被整合进了顶部搜索栏(Tell me what you want to do),用户可以用自然语言直接搜索功能和操作指引。考虑到 Jamovi 已经走在这条设计路径上,引入一个搜索式的帮助入口是自然的延伸:在顶部功能区提供搜索框,支持文档和功能名称的全文搜索,搜索结果直接链接到对应的界面元素或帮助页面。
零碎的小麻烦
此外还有两个较小但值得一提的问题。一是 macOS 适配:有参与者发现 macOS 顶部菜单栏的 File 菜单缺少 Open 功能,违反了平台设计惯例;专家评估中也有人指出 macOS 用户可能使用 Numbers,但 Jamovi 不支持导入这种格式。
翻译质量亦有较大优化空间,有三名实验参与者面对母语界面感到彷徨无措,打开软件后的第一件事就是干脆切换成英文界面。
结语
Jamovi 是一个开源软件,设计者大多是统计学家,用户体验设计从业者很少。这意味着这个领域的用户体验研究是稀缺的。此外,这类软件既不商业,又比商业产品更难做。你不能假设用户都来自同一个心智模型,因为他们可能来自 Excel、SPSS、Stata、GraphPad、 R 任何一个生态。我希望这份报告能为 Jamovi 社区提供一些有用的输入。
如果你也在为某个开源项目做用户体验工作,欢迎和我交换彼此的经验和困惑。
以上就是今天全部的分享了,莉莉爱你 ♥~
由于研究者的失误,量表遗漏了「Performance」维度。因此这个得分无法与标准常模直接比较,仅作为参与者之间的相对参考和主观负荷的粗略指标。 ↩︎
我们后续以 Jamovi 为核心展开了一个实验性的统计素养 Workshop,此问题在 Workshop 中也至少出现了两次,可见其严重程度。 ↩︎
在正式测试前,我们系统评估了主流的 Computer Use 自动化平台。几乎所有主要的「Claw」类平台都存在严重的工程质量问题:有的平台 API 网关 URL 存在字符串拼接错误导致无法稳定连接后端;有的平台上下文压缩机制存在逻辑缺陷,压缩过程本身消耗的上下文空间比释放的还多,导致后端崩溃。最终选择了 AstrBot 作为实验基础设施,它是唯一一个管理面板完整无 bug、MCP 工具调用和上下文管理全部正常工作的平台。 ↩︎


Loading comments...