

尽管刷榜刷得一套一套的,但如果你真的用 LLM 做一点「人事」的话,会发现最近这些新模型的实际能力并没有很相称。在我看来,这是当代「古德哈特定律」的魅力时刻:当一个评价指标本身成为优化的目标时,它便不再是一个良好的指标。
这两年我们能看到的最丢人的两个例子便是来自 Facebook 的 LLAMA 4。这模型为了追求跑分搞了作弊的伎俩,被整个社区拉出来鞭,只能说是非常丢人了。
大语言模型本身是为了解决人类问题而发展出来的东西,但是人类并不像水里游的鱼,把吃饭和传宗接代解决就算大功告成。人类的想要解决的问题是多元且复杂的。任何考验单一能力的 Benchmark 都不能够准确的评断我们日常需要执行的的所有认知任务。特别是写作这种很吃主观品味的东西。DeepSeek 刚出的时候,大家都非常喜欢那种狂飙形容词、 MSG 味很浓的文字,但后期这类东西开始在互联网上泛滥之后,就变得人见人打了。

组合多个多个 Benchmark 来衡量模型品质同样不是一种万金油式的思路,因为「语言能力」是一种相当不好量化的事情。可能语法正确错误还有得聊,但语言风格这件事情就很难说了,有人偏好浮夸的遣词用字,有人喜欢平实的表达方式。因此,模型换代带来的风格变化几乎必然招致社群当中相当多的一部分人抱怨。
语言能力本身难衡量是一方面,模型厂商出于各种目的往模型里面加料则是另外一方面。模型训练不是把所有资料从头舔到尾就算完事的。厂商还会处于各种目的在后面追加一步 RLHF 微调,来做安全性对齐、语言风格调整以及一些功能性增强。已经有很多研究印证了后面加的这些微调会对模型本身的语言能力产生消极影响。包括但不限于降低输出多样性,使模型产出的文本变得更重复、更低熵、措辞和视角更单一。你想在本来天马行空的模型上面砍掉一些东西相当容易,但是想通过微调让它「长出多样性」就很难,因为它的标准不好界定,一旦你给出了一些可以衡量的标准,这些标准就会变成单调的源头。
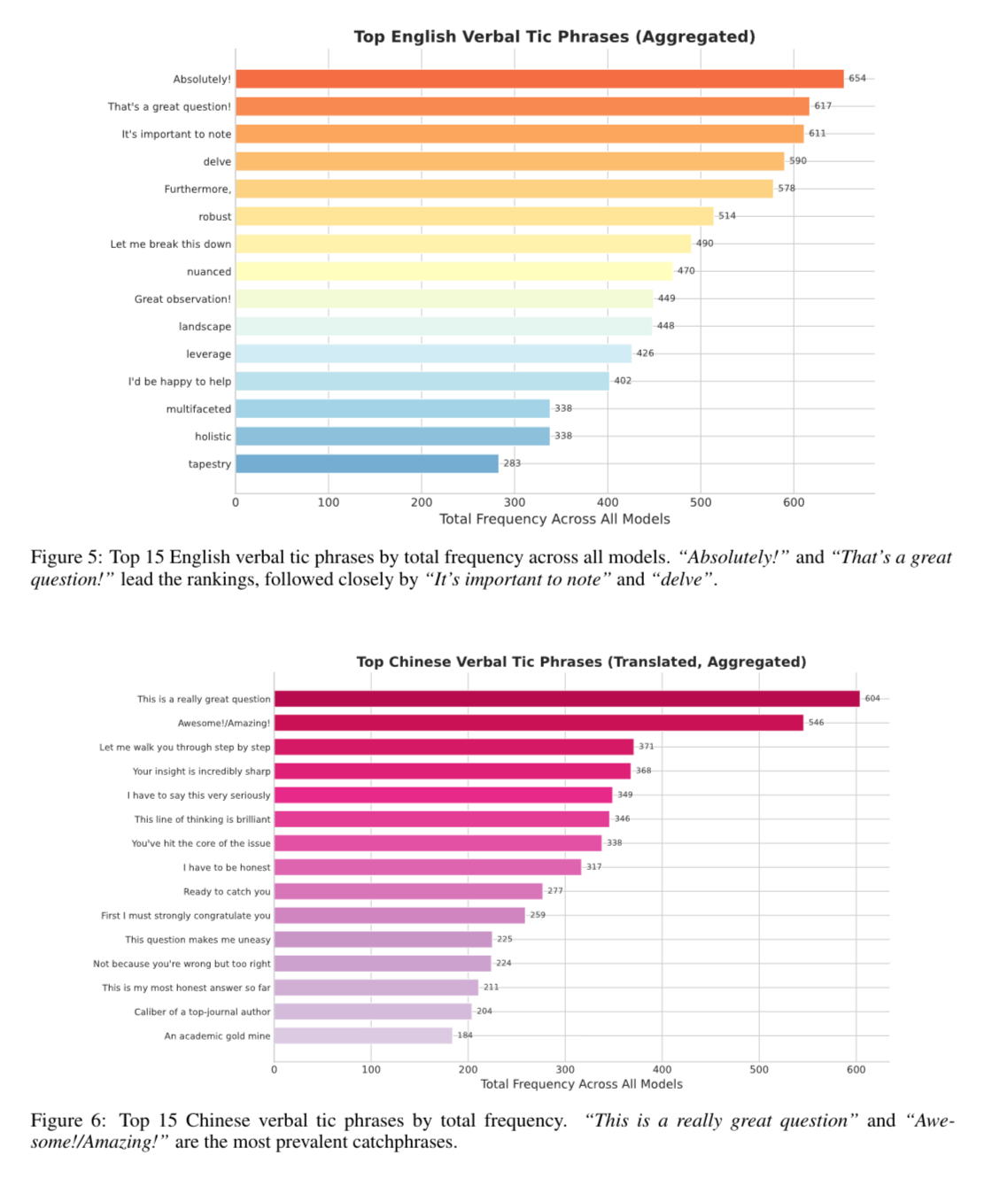
GPT 5 开始出现的大量谄媚表述、滥用单字汉字词、令人烦躁的口癖,Grok 不长脑子的自来熟、DeepSeek 的致死量形容词名词叠叠乐,还有 Claude 的「是诚实的」、「我必须诚实」一看就是后训练的时候把「Honest,会就说会不会就说不会」当成标准,导致此表达开始爆炸般地变多。这类微调在最近一两年的模型当中被做得越来越多,下手越来越很,口味越来越重。在我看来这是必然的事情,因为人们对大语言模型的期待和想象只会变得越发细致和具体,而这每一条期待都是束缚大语言模型表达的枷锁。
何其讽刺。
你可能听说过现在人类产出的文本几乎都已经被大语言模型拿去训练了,而且现在的大语言模型本来就已经在用各种正则化的方式对抗本就尴尬的样本量不足问题。为了进一步扩张参数规模,各家会开始用合成数据、蒸馏同行的输出结果。哪怕能通过爬虫爬到互联网上新产出的内容,你也爬不出什么纯粹的人类智慧了。2025 年 5 月 Ahrefs 发布了一个研究,揭露了这个问题。它们开发了一个内部 AI 内容检测器,对 2025 年 4 月被爬虫新发现的 90 万个英文网页进行了分析,每个域名取一个页面,覆盖 90 万个不同域名。结果发现 74.2% 的新网页包含 AI 生成内容,只有 25.8% 被归类为纯人工撰写。其中 71.7% 属于人机混合内容。
AI 生成出来的文本不会给模型本身提供太多的新信息(是的,有新信息,但是非常有限)。其结果是,如果人们过度依赖被重口味调教过的模型,其产出的同质化内容再被重新灌回去训练模型,那么整个训练过程将会不可避免地持续劣化输出结果。只有分数变得越来越漂亮,可用性却变得越来越低。
更让人绝望的是,如果你显式地用提示词工程要求 LLM 「不要这样说话」,它几乎没办法做到。具体地说,它有的时候会忘记要求,有的时候会开始变得不说人话。
我有的时候会混用新旧模型,用推理能力更强的新模型做研究任务,用口味没那么重的旧模型整理结果。但是模型并不能精确产出,一旦它尝试用通俗的方式解释研究结果的时候就有犯错的可能,一丝一丝纠那些措辞问题也是一件很疲劳的事情,很多时候甚至不如自己从头到尾写一遍来的轻松。统计学话题是重灾区,因此我真的不建议社科的朋友用 LLM 搞论文。我之前也写过一篇文章讲你为什么不应该用 LLM 讲统计,你感兴趣的话推荐去读一读。
让我们把视角转向使用 LLM 写作的作者。微妙的是,作者本身可能没有办法在 LLM 辅助写作的当下就意识到输出内容的语言风格。包括我在用 Arena 训练自己识别大语言模型风味之前,也对其没有过多感受,但现在回看之前过于 Vibe 的文章时还是会觉得相当羞愧。我认为开始使用 Arena 对 LLM 的输出进行盲评,并训练出对 LLM 输出文本风格的敏感度是当代作者的必修课。在大量使用 LLM 行文之后,把文章压在稿箱里面,等三天之后从整个创作环境当中充分抽离之后再检查文本,是一个必要的习惯。它是这个时代作者的展现出谦卑的美德。
我希望各位能够理解一个重要的事实,用提示词工程做语言风格约束,其帮助相当有限。哪怕你告诉它不要用「不是、而是」,它输出的内部行文逻辑依然有可能是拉踩结构。我已经发现不止一个媒体老师出的稿子里面闹这个问题了。另外,在一些视频创作者的作品中突然蹦出一段内容,巨长比例变得无比规整,个人风格开始变得稀薄,我立刻就能嗅到这边是写不出来东西了,拿 LLM 随便写了点什么糊上去的。
这当中不乏很多知名且曾经能力透纸背的媒体创作者,比如某知名商业分析频道、某 Minecraft 频道、某几个数码频道。有的时候味道太冲我看不下去的时候,我会非常懊恼地点一个不喜欢,并且在评论区里面毫不客气地指出滥用 LLM 创作的问题。他们会读么?会「改」么?或者说,这是一件需要被纠正的事情么?
把这个「问题」打开看,其中有一些是写作技术问题,有一些是创作者心态的问题。很多以文字或「内容」糊口的创作者,其创作过程天然地带一点 Farming 的味道。毕竟每周准时准点发稿发片才能养的起公司的人。过去,在这些压力下被产出的可能是没那么准确的科普、和略显笨拙的遣词造句。它们究竟是「良性的有机」还是「劣质的作品」,这件事情可以任人解释。毕竟先前我在一大早打开前司 NAS 看到 A Copy 里面胡乱解释 p 值的时候也血压高了好几个小时,我不能说过去的「不完美」是一个好的东西。但是在 LLM 大行其道的当下,这些「多样的缺陷」被同一种调料抹平,在我看来是一件很可惜的事。

Loading comments...